What Is Centralized Management? Control AI & Costs in 2026

You shipped your first AI feature fast. Maybe it was a support copilot, a content helper, or an image generation flow. At first, the setup looked manageable. A prompt in the codebase, one API key in an environment variable, one model choice hardcoded behind a button.
Then reality showed up.
A teammate changed a prompt directly in production code. Another feature started using a different provider. Your logs told you a request failed, but not which prompt version caused it, which model handled it, or why the response got expensive. Bills arrived from multiple vendors. Debugging meant searching app logs, cloud logs, and provider dashboards at the same time.
That's the moment most founders start asking a broader question: what is centralized management, really? Not the old textbook answer. The modern one. The one that matters when your product depends on text, image, audio, or video models that can change cost, latency, and quality from one release to the next.
In the AI era, centralized management means running your AI features from one operational control layer. One place for prompts, routing rules, fallbacks, logs, and spend visibility. It's how you stop AI from becoming a collection of expensive, fragile shortcuts.
Table of Contents
- The Hidden Chaos of Building AI Features
- Unpacking Centralized Management From First Principles
- Core Components of a Centralized System
- Centralized vs Decentralized Management A Clear Comparison
- Putting It Into Practice How AI Teams Implement Centralized Management
- Key Metrics and Common Pitfalls to Avoid
- The Future Is Hybrid Centralized Oversight with Decentralized Execution
The Hidden Chaos of Building AI Features
AI projects rarely break all at once. They get messy in layers.
First, prompts end up scattered across endpoints, background jobs, and feature flags. Then model choices spread too. One part of the app calls OpenAI, another calls Anthropic, another uses an image model, and nobody owns the full picture. Soon your team can answer simple product questions only by guessing. Which model handled this customer request? Why did yesterday's output quality drop? Why did a minor prompt tweak change cost behavior?
That's not a tooling problem alone. It's a management problem.
Traditional definitions of centralized management talk about executives making decisions from the top. That matters in org design, but it misses what founders need when shipping AI. In an AI system, many important “decisions” aren't made in meetings. They happen in request flow. Which model gets selected. When a fallback triggers. How output format gets enforced. Whether a request goes to a text model, an image model, or a cheaper backup.
Practical rule: If your team can't answer prompt version, model choice, latency, and cost from one place, you don't have control. You have scattered implementation details.
This is why centralized management matters now more than the old business-school definition suggests. It gives your team one control layer for AI behavior. Instead of burying logic inside app code, you manage the moving parts where they belong: in a shared operational system.
For a non-technical founder, the simplest analogy is a restaurant with no pass at the kitchen line. Every cook is making changes independently, tickets are coming from different printers, and no one sees the full room. You might still serve meals, but waste goes up, mistakes pile up, and fixing service becomes chaotic.
A centralized setup gives you the pass. Orders flow through one visible place. Standards get applied consistently. Problems surface early. Time and money stop leaking through invisible gaps.
Unpacking Centralized Management From First Principles
Centralized management is an old idea because large systems have always needed coordination. It became especially influential in the industrial era, when growing organizations needed a single control point to coordinate labor, inventory, and production across larger operations, as described in this overview of centralized management and modern command structures.
For AI teams, the best analogy is an airport control tower.
Planes still fly independently. Pilots still do real work in the air. But the tower keeps the shared picture. It tracks traffic, prevents conflicts, coordinates resources, and gives one trusted view of what's happening. That's what centralized management does in modern systems. It doesn't remove all local action. It creates a common operational layer so local action doesn't become disorder.

Why the idea has lasted
The reason this model keeps showing up in different industries is simple. Once a system gets big enough, inconsistency becomes expensive.
The same healthcare review noted in the source above found that centralized command centers improved integration of multiple services, communication and coordination, and prediction or early warning. It also reported that, across the studies reviewed, most showed optimized resource utilization and most showed optimized operations or care delivery. That matters because it shows where centralized management usually helps first. It improves process control before it improves final outcomes.
That maps neatly to AI products. Before centralization improves revenue or retention, it usually improves the operation around the feature. Debugging gets easier. Model changes get safer. Teams spend less time hunting for information.
The three pillars that matter
You can strip the whole concept down to three practical pillars.
Visibility comes first because teams can't manage what they can't see. If ten different endpoints call ten different models with ten different logging styles, you don't have operational awareness.
Control is the next layer, a concept that often confuses readers. Control doesn't mean every decision waits for a CEO or staff engineer. It means the system rules live centrally, even if many people operate within those rules.
Centralized management is less about micromanaging every action and more about keeping the important levers in one trusted place.
Consistency is the payoff. Customers get more predictable behavior. Engineers get fewer surprises. Founders get fewer expensive fire drills.
Core Components of a Centralized System
If centralized management sounds abstract, it helps to name the actual parts. In a software system, centralization is visible in the architecture.
NIST defines centralized management as organization-wide management and implementation of selected security and privacy controls, including planning, implementing, assessing, authorizing, and monitoring centrally managed controls and processes, in the NIST glossary entry for central management. The practical point is clear. One authority sets the rules, applies them consistently, and can audit them later.
The parts you can actually point to
Most centralized systems include a handful of recognizable components.
- A central dashboard gives the team a single operating view. In AI work, that means seeing requests, failures, latency, token usage, I/O, and costs without switching tabs across providers.
- An API gateway or unified entry point acts like a front desk. Instead of every product feature talking directly to every model provider, requests go through one layer that can apply policy, routing, and logging.
- A rule engine decides what should happen under certain conditions. If the prompt requires structured JSON, route one way. If the image model times out, trigger a fallback. If cost crosses a threshold, prefer a different model path.
- A centralized logging and observability layer records the full request story. Not just that a call happened, but which prompt version ran, which model answered, how long it took, and what it cost.
- Version control for prompts and parameters keeps behavior auditable. When output changes, the team can trace whether the cause was a prompt edit, a model switch, or a parameter change.
Why these parts work together
Each part solves a different failure mode.
Without a dashboard, leaders lose visibility. Without a gateway, every team invents its own connection logic. Without rules, routing becomes tribal knowledge. Without logs, debugging becomes archaeology. Without versioning, teams argue about what changed because nobody can prove it.
Here's the important distinction. A centralized system doesn't require one giant app that does everything. It requires one governing layer that standardizes how critical actions happen.
Operating principle: Centralization works when teams keep local execution flexible but keep policy, logging, and control logic shared.
That's also how centralized systems reduce configuration drift. If one team updates retry behavior, another team shouldn't inadvertently keep old logic for months. Shared management prevents that slow divergence.
For founders, the business value is straightforward. The more AI features you ship, the more expensive inconsistency becomes. Centralized components are what keep the cost of coordination from overtaking the speed of development.
Centralized vs Decentralized Management A Clear Comparison
The core question usually isn't whether centralization is good or bad. It's where decision authority should live.
In organizational terms, centralized management means final decision authority stays at the top of the hierarchy, with executives or a small leadership group making core planning and strategy decisions while others execute them, as outlined in this explanation of how centralized management works in organizations. That structure improves consistency and accountability, but it can also create bottlenecks.
That tradeoff exists in software too.
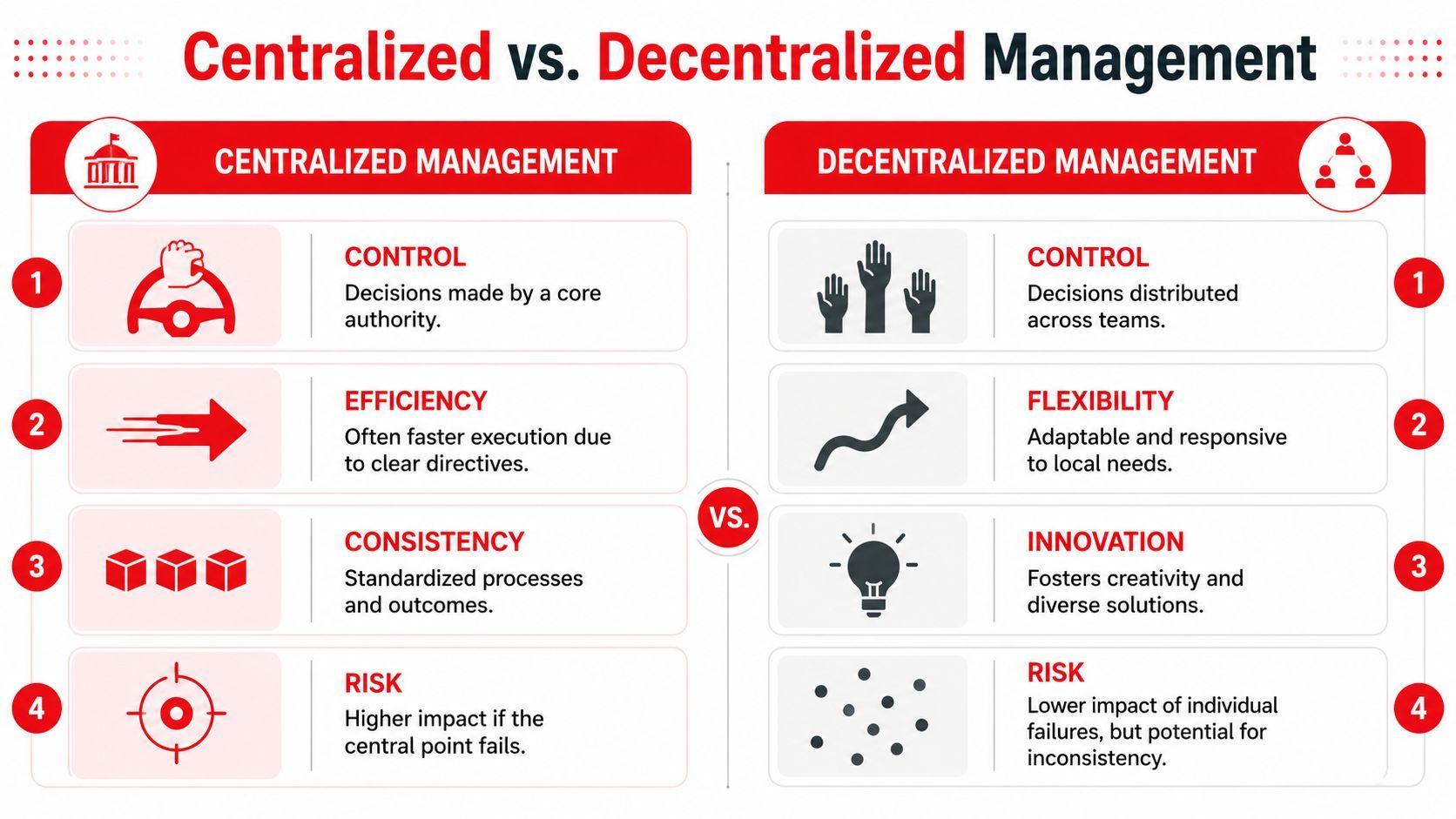
Where authority lives
A decentralized setup gives individual teams more autonomy. They can pick their own models, prompts, providers, and release cycles. That can feel fast early on because nobody waits for shared process.
But the cost shows up later. Two teams solve the same problem differently. Logging formats don't match. Cost controls vary. Security rules drift. Nobody owns the cross-product view.
A centralized setup does the opposite. It puts the important operational rules in one place. That slows down some local freedom, but it creates one standard for visibility and governance.
Here's a simple comparison:
Which model fits AI operations
For AI products, pure decentralization usually breaks down once you have multiple features and providers.
Why? Because AI behavior is no longer just code behavior. It's also vendor behavior, prompt behavior, model behavior, and fallback behavior. If each team manages those pieces alone, you get local speed at the cost of global confusion.
That doesn't mean every choice must be centralized. Product teams still need room to test prompts, try a different model, or adjust user experience. The key is deciding which decisions are local and which are shared.
A healthy pattern often looks like this:
- Centralize governance: routing rules, spend visibility, audit logs, security policies
- Decentralize product iteration: feature-level prompt testing, UX changes, experimentation inside guardrails
- Centralize reporting: one place to review failures, latency patterns, and usage
If decentralization lets every team move fast in a different direction, centralization makes sure they're still building one company.
For founders, that balance matters. You want teams to ship quickly, but you also need one answer to simple operational questions. What are we spending? What changed? Which feature failed? Who owns the fix?
Putting It Into Practice How AI Teams Implement Centralized Management
A founder usually notices the need for centralized management at the same moment operations start feeling expensive and unpredictable.
One team ships a support copilot on one model. Another adds image analysis through a different provider. A third experiments with voice. A month later, nobody can answer simple questions with confidence. Which feature is driving spend? Why did response quality drop last Thursday? Which fallback ran when a provider timed out? The product may look unified to customers, but behind the scenes it has become a pile of separate AI decisions.
AI teams fix that by placing a unified backend layer between the product and the model providers it uses.
What a unified AI backend does
A unified backend works like a control tower for AI traffic. The application sends one request in. The backend applies the rules that decide where that request should go, how it should be handled, and what should be recorded.
That matters more in the AI era than older definitions of centralized management suggest. Traditional centralization often meant approval chains and shared reporting. Modern AI teams need something more operational. They need one layer that can handle text, images, audio, prompt versions, provider failover, and cost controls without forcing every product team to rebuild the same logic on its own.
Here is what happens inside that layer:
- Prompt management keeps prompts versioned, testable, and easier to roll back
- Provider abstraction lets one product integration work across several model vendors
- Model routing sends each request to the model that fits the job, budget, and latency target
- Fallback logic keeps a temporary provider or model issue from breaking the feature
- Observability records what happened on each request so teams can debug and improve it
- Cost tracking ties usage and spend back to features, flows, or customers
Model routing is often the first concept that sounds more complex than it is. It is a rules engine for choosing the right tool for the task. A short classification task may go to a smaller, cheaper model. A document summary may go to a stronger text model. An image request may go to a vision model from another provider. Without a central layer, those choices get buried in separate services and frontend code, which makes every change slower and riskier.
One example is Supagen's unified AI backend, which provides centralized prompt management, model routing, fallbacks, and per-call observability for multi-modal workloads through a single integration.
How teams change prompts without painful redeploys
Early AI features often start with prompts hardcoded into application logic. That is fine for a prototype. It becomes costly once prompts start changing every week.
Then a small wording update turns into an engineering task. A provider switch becomes a release. A safety fix has to wait for a deployment window. The team is spending senior engineering time on configuration work.
Centralized management changes that operating model. Prompts, routing rules, and fallback policies move into a shared control layer, where teams can update them through governed configuration instead of scattered code edits. That makes changes easier to review, compare, approve, and reverse.
Here's a useful walkthrough if you want to see how teams structure that control layer in practice.
Observability is the other piece founders often underestimate.
In plain language, observability means leaving a readable trail for every AI request. If a customer reports a bad answer, the team should be able to see which prompt version ran, which model handled the request, how long it took, whether a fallback fired, and what it cost. Without that trail, debugging becomes guesswork. With it, the team can find the exact point of failure and fix the right thing.
That is why centralized management for AI is not just about control. It is about reducing repeated work, containing model sprawl, and giving every team one backend approach for running multi-modal AI features without operational chaos.
Key Metrics and Common Pitfalls to Avoid
A centralized system is only useful if it helps your team run AI features better. That means watching a small set of operational metrics and avoiding the mistakes that make centralization feel heavy.
Evidence from large distributed environments shows why this matters. Central monitoring is valuable where systems need standardized oversight and rapid anomaly detection, and it can identify discrepancies across multiple sites earlier than local review alone, reducing the chance of costly rework late in the process, as discussed in this analysis of centralized data and monitoring.
The metrics worth watching
Don't start with vanity metrics. Start with the ones that help you make decisions.
- Latency by request type tells you where the user experience is slowing down. Break it down by feature, provider, and model path instead of looking at one blended average.
- Cost per feature flow shows which product experience is actually expensive. “AI spend” as one combined number is too broad to guide product decisions.
- Failure and fallback rates reveal whether the system is stable. If one route fails often and falls back to another, that's not just reliability data. It's also cost and quality data.
- Time to debug is a practical internal metric. If a production issue still requires multiple people pulling logs from multiple tools, your centralized layer isn't doing enough yet.
- Change traceability matters more than many founders expect. When output quality changes, your team should be able to tell whether the cause was a prompt edit, parameter change, or provider switch.
Good observability turns “something feels off” into “this prompt version increased failures on this route.”
Mistakes that turn centralization into a bottleneck
The first mistake is centralizing every tiny choice. That creates a queue, not a system. Teams should not need a committee meeting to test wording or improve UX.
The second is over-engineering early. You don't need a giant control plane on day one. You need a clear shared layer for prompts, routing, logging, and spend. Build enough structure to stop chaos, not enough structure to impress architects.
A few failure patterns show up often:
- One giant approval process slows down product teams and makes them bypass the system.
- Missing ownership leaves the “central” layer unmanaged, which means it becomes another neglected tool.
- Bad instrumentation produces lots of logs but little usable context.
- No team buy-in turns centralization into an imposed constraint instead of a helpful operating model.
A better approach is narrower and clearer. Keep standards centralized. Keep experimentation inside guardrails. Make the dashboard useful enough that teams want to use it.
The Future Is Hybrid Centralized Oversight with Decentralized Execution
The most practical answer to what is centralized management in 2026 isn't “everything from the top.” It's centralized oversight with decentralized execution.
That matters because modern AI systems aren't single pipelines anymore. They're networks of features, tools, agents, providers, and modalities. Some requests need text generation. Others need image synthesis, audio, retrieval, or structured JSON. Teams need flexibility close to the work. Leadership still needs one place to govern cost, quality, and reliability.
So the winning pattern isn't rigid central control. It's a hybrid.
The central layer owns the shared concerns: routing policy, observability, auditability, and spend visibility. Product teams and agents execute within that layer. They can move fast, but they don't disappear into black boxes.
This is the part many older definitions miss. In AI, decentralization doesn't have to mean operational blindness. You can let agents and teams act independently while still keeping the rules, logs, and financial controls centralized.
For founders, the takeaway is simple. If your AI product is growing, you should audit where control lives today. Are prompts hardcoded? Are model choices scattered? Can anyone explain cost spikes quickly? Can your team change behavior without risky redeploys?
If the answer is no, centralization isn't bureaucracy. It's overdue infrastructure.
If you're building AI features and want one place to manage prompts, model routing, fallbacks, observability, and cost tracking, Supagen is one way to put centralized management into practice without hardcoding those concerns into your app.