Mastering Tokenizing a String in Python, JS & Java

You're probably dealing with one of two problems right now.
Either you have ordinary application text, search queries, feedback, transcripts, CSV blobs, chatbot messages, and you need to break that text into usable pieces. Or you're building on top of LLM APIs and suddenly “how many tokens is this?” has become a cost, latency, and reliability question instead of a minor implementation detail.
That's why tokenizing a string matters more than most tutorials admit. In the simple case, it decides whether your search, parser, or classifier behaves sensibly. In the LLM case, it decides how much context you can fit, how much you pay, and whether multilingual users become more expensive to serve than English-speaking ones.
Table of Contents
- What Is Tokenization and Why Does It Matter
- The Fundamentals of Simple String Tokenization
- Handling Real World Text with Regex and Libraries
- The New Frontier Tokenizing for Large Language Models
- Token Accounting Observability and Streaming
- Frequently Asked Questions about String Tokenization
What Is Tokenization and Why Does It Matter
A user pastes a 2,000 word support transcript into your app. The search index misses key phrases, your analytics job overcounts junk terms, and the LLM summarizer costs more than expected. In all three cases, the root problem is often the same. You did not define what a token should be for that job.

Tokenization turns raw text into smaller units a program can process. Those units are tokens. Depending on the system, a token might be a word, a punctuation mark, a sentence, or a subword fragment. That last category matters more now than it used to, because modern LLM APIs bill, limit context, and stream output in token-sized pieces rather than in human-friendly words.
If you have ever written text.split(" "), you have already tokenized a string. That works for controlled input and quick scripts. It breaks fast once text starts carrying structure, ambiguity, or cost.
mother-in-law, C++, women's, New York, and 👍🏽 all force a choice. Should each be one token, several tokens, or something normalized before tokenization even starts? As noted earlier, SMLTAR's guide describes tokenization as a boundary-definition problem, where you choose split-based or extract-based rules and validate them against real input rather than assuming split() captures meaning.
Tokenization is boundary-setting
In practice, tokenization is less about cutting on spaces and more about deciding what your application is allowed to treat as a unit.
That decision affects behavior upstream and downstream. Search quality changes if hyphenated terms stay intact. Analytics changes if punctuation is dropped or preserved. Entity extraction changes if multi-word names are split too early. LLM behavior changes if you trim prompts by characters instead of by model tokens.
I treat tokenization as application logic whenever the output feeds anything user-facing, billable, or hard to debug later.
Why it matters in both old and new stacks
Traditional software uses tokenization to support work such as:
- Search indexing: deciding whether variants like
run,running, andrunnershould map together - Text analytics: counting terms, phrases, and recurring topics without filling reports with noise
- Parsing pipelines: turning messy free-form text into fields, labels, or entities
Modern AI systems add a second layer of pressure:
- Model input preparation: text must be converted into token IDs before a model can read it
- Context management: token limits are usually tighter than teams expect, especially once system prompts, tools, and conversation history are included
- Cost and latency control: more tokens usually mean more spend, slower responses, and less room for useful context
That trade-off is the part many older string-processing tutorials skip. In a classic ETL pipeline, weak tokenization might produce messy counts or brittle parsing. In an LLM product, the same mistake can waste context window, hide prompt bloat, and increase API spend on every request.
Good tokenization starts with a simple question. What should count as one unit in this system, and what does it cost if that choice is wrong?
The Fundamentals of Simple String Tokenization
The starting point for tokenizing a string is still the built-in split method. It's fast, readable, and built into the languages commonly used.
If your input is predictable, this is a fine first pass.
Basic split examples in Python JavaScript and Java
Python
text = "tokenizing a string with simple whitespace rules"
tokens = text.split()
print(tokens)
# ['tokenizing', 'a', 'string', 'with', 'simple', 'whitespace', 'rules']JavaScript
const text = "tokenizing a string with simple whitespace rules";
const tokens = text.split(/\s+/);
console.log(tokens);
// ['tokenizing', 'a', 'string', 'with', 'simple', 'whitespace', 'rules']Java
public class Main {
public static void main(String[] args) {
String text = "tokenizing a string with simple whitespace rules";
String[] tokens = text.split("\\s+");
for (String token : tokens) {
System.out.println(token);
}
}
}These examples all split on whitespace. That works when the text is clean and your definition of a token is “chunks separated by spaces.”
Where simple splitting breaks
Real input stops cooperating almost immediately.
Take these examples:
The edge cases that bite most often are not exotic. They're ordinary language features.
According to Query Understanding's tokenization discussion, binary splitting strategies fail on apostrophes, hyphenated compounds, and contractions. It specifically highlights that tokenizing women's as a single unit versus splitting it into women and s can materially change model reasoning and embedding quality.
If your tokenizer destroys meaning before search or embeddings ever see the text, the downstream model can't recover it.
When split is still the right choice
Built-in split methods are still useful when all of these are true:
- Your delimiter is stable: CSV-like internal formats, log lines, or tab-separated fields.
- You control the input: You generated the text yourself and know its structure.
- You only need rough chunks: Quick scripts, debugging tools, or basic preprocessing.
When those conditions don't hold, .split() becomes less of a tokenizer and more of a blunt instrument.
A practical habit is to start with split only if you can write down the failure cases you're willing to accept. If you can't, move up a level and define token boundaries explicitly.
Handling Real World Text with Regex and Libraries
A tokenizer that looks fine on a demo string can fail the first time it sees a customer name, a SKU, a URL, and an emoji in the same line. That is usually the point where teams stop treating tokenization as string cleanup and start treating it as a boundary-definition problem.
You have two practical tools for that job. Write explicit extraction rules with regex, or use a library that already knows how to handle messy text. The trade-off is straightforward. Regex gives tight control and predictable output. Libraries reduce the amount of Unicode, normalization, and edge-case behavior your team has to maintain.

Regex gives you control
Regex works best when you want to define what a valid token is. That is a better fit than splitting on separators once punctuation carries meaning.
Here's a practical Python example:
import re
text = "women's rights and state-of-the-art tools"
tokens = re.findall(r"[A-Za-z]+(?:['-][A-Za-z]+)*", text)
print(tokens)
# ["women's", 'rights', 'and', 'state-of-the-art', 'tools']JavaScript version:
const text = "women's rights and state-of-the-art tools";
const tokens = text.match(/[A-Za-z]+(?:['-][A-Za-z]+)*/g) || [];
console.log(tokens);
// ["women's", "rights", "and", "state-of-the-art", "tools"]Java version:
import java.util.regex.*;
import java.util.*;
public class Main {
public static void main(String[] args) {
String text = "women's rights and state-of-the-art tools";
Pattern pattern = Pattern.compile("[A-Za-z]+(?:['-][A-Za-z]+)*");
Matcher matcher = pattern.matcher(text);
List<String> tokens = new ArrayList<>();
while (matcher.find()) {
tokens.add(matcher.group());
}
System.out.println(tokens);
}
}That pattern keeps internal apostrophes and hyphens, which is enough for many English-heavy pipelines.
It also has clear limits. [A-Za-z] will miss accented characters, many non-Latin scripts, and some domain-specific tokens such as v2.1, C++, or user_name. Regex is still a good choice in log processing, product catalogs, and search preprocessing where the allowed token shapes are known in advance. In those cases, strictness is a feature because deterministic token boundaries make indexing and debugging easier.
Libraries reduce the edge cases you own
Library tokenizers earn their keep when the input is unpredictable or multilingual. They usually combine token rules with Unicode awareness, normalization, and sentence segmentation, which saves a lot of custom patching later.
A few common picks:
- Python with NLTK or spaCy: Good for NLP workflows where tokenization feeds tagging, parsing, or embeddings.
- JavaScript with Compromise: Useful for lightweight tokenization and text analysis in web apps or Node services.
- Java with OpenNLP or Lucene analyzers: A practical fit for search systems and enterprise Java stacks.
The cost is less obvious behavior. Libraries make judgment calls about punctuation, abbreviations, and language rules, and those choices may not match your product requirements. If tokenization affects compliance rules, search ranking, billing, or any user-visible output, inspect the actual tokens instead of trusting the defaults.
Choose based on failure cost
The decision is less about elegance and more about what happens when the tokenizer is wrong.
Use regex when:
- You have stable domain rules: SKUs, hashtags, invoice IDs, log fields, or controlled content formats.
- You need deterministic output: The same input should always produce the same tokens with no hidden normalization.
- You care about runtime and dependency size: Small services and utility scripts often do better with one explicit pattern than a full NLP stack.
Use a library when:
- You need broad language coverage: Unicode-aware token boundaries matter.
- You expect ugly text: Scraped pages, transcripts, chats, OCR output, and user-generated content break simplistic rules fast.
- You will reuse the output downstream: Search, embeddings, named entity recognition, and analytics benefit from consistent preprocessing.
One more practical point matters here. Traditional tokenization choices can affect LLM costs later. If an early preprocessing step preserves meaningful units cleanly, prompts are easier to chunk, deduplicate, and measure before they ever hit a model API. If it shreds text into noisy fragments or leaves junk attached to every token, you pay for that mess twice. Once in downstream quality, and again in extra tokens sent to the model.
Test against real input, not the example you wrote for yourself
A tokenizer should be evaluated on the text your system sees. Include multilingual samples, malformed punctuation, abbreviations, URLs, product names, contractions, and copy pasted text from spreadsheets or PDFs.
That is where weak rules show up.
Two habits improve results quickly:
- Keep punctuation only when it carries meaning inside the token. Apostrophes, hyphens, decimal points, and plus signs are common examples.
- Build a small regression set from production text. Every time tokenization fails, add that case and lock in the expected output.
Teams that do this usually stop arguing about tokenizer style and start shipping rules that survive contact with real data.
The New Frontier Tokenizing for Large Language Models
A prompt that looks short to a human can still be expensive to a model.
That catches teams the first time they ship an LLM feature at volume. The string looks clean in logs, the UI copy feels compact, and the request still burns more context and money than expected. Traditional tokenization helps you find meaningful text units for search, parsing, or analytics. LLM tokenization serves a different job. It converts text into a reversible sequence the model can encode efficiently, price consistently, and fit inside a context window.
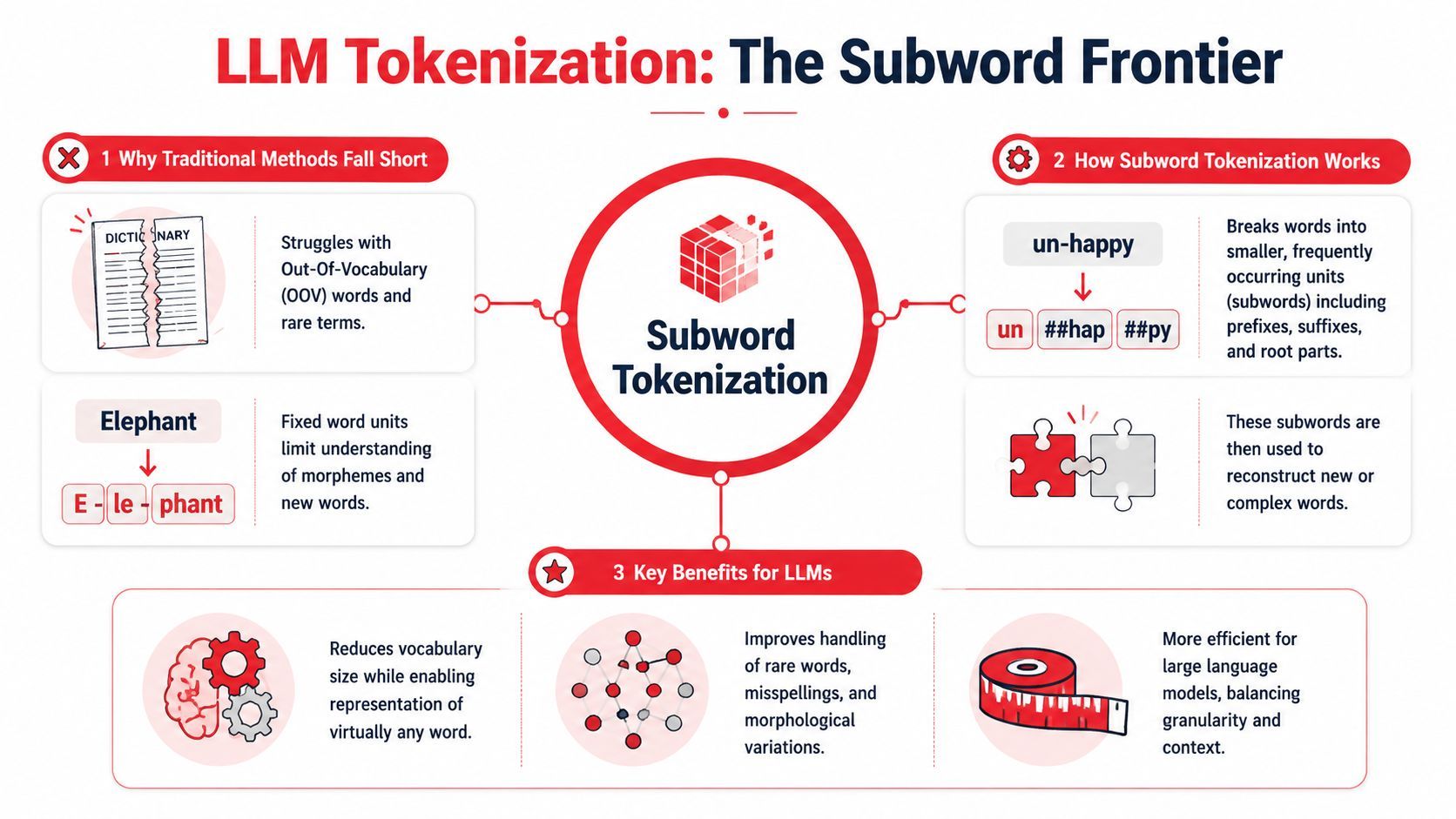
Modern LLM tokenizers usually do not operate at the whole-word level. They start from bytes or characters, then merge frequent adjacent units into larger tokens. The result is a subword vocabulary that handles common patterns compactly while still representing rare strings, code, typos, and multilingual input without losing reversibility.
That design choice matters for two reasons. It keeps the model from failing on unfamiliar text, and it reduces the number of tokens needed for common sequences compared with pure character-level encoding.
Why LLMs don't just split on spaces
Space-based tokenization breaks quickly once real product traffic shows up. Usernames, JSON, stack traces, contractions, emojis, product SKUs, and mixed-language text all create edge cases. A word-level vocabulary also struggles with out-of-vocabulary terms. You either explode the vocabulary size or accept poor coverage.
Subword tokenization is the practical compromise. Frequent fragments become single tokens. Uncommon strings fall back to smaller pieces. The model can still reconstruct the original text exactly.
That gives you a few concrete advantages:
- Coverage: Arbitrary input still encodes cleanly.
- Compression: Repeated patterns often consume fewer tokens than character-level schemes.
- Reversibility: The encoded sequence can decode back to the original text.
Here's the embedded overview if you want a quick visual explanation:
The part that affects cost
For LLM systems, tokenization is part of the cost model.
Providers bill by tokens. Context limits are measured in tokens. Latency is often tied to how many tokens you send and generate. That means tokenization is no longer just a preprocessing detail. It affects prompt design, retrieval size, caching strategy, and whether a feature remains profitable under production traffic.
I treat this as a systems concern, not a text-cleaning concern. A verbose system prompt, oversized retrieval chunks, or noisy OCR output can all inflate token counts before model quality even enters the discussion. Better token efficiency gives you more usable context for the same budget, or the same result for less money.
The multilingual cost trap
This gets sharper in global products.
Research summarized in this arXiv analysis of ten popular language models found that tokenizers are not language-neutral, and that low-resource languages can carry tokenization premiums that raise API costs by up to 30-40% for non-English users. If your evaluation set is mostly English, you can miss a meaningful cost difference between markets even when the feature looks identical at the product layer.
I have seen teams blame model pricing first. Sometimes the cheaper fix is upstream. Shorter templates, tighter retrieval, or language-aware prompt design can reduce waste before you consider switching providers or downgrading model quality.
Multilingual cost control starts with the tokenizer, because the tokenizer determines how much text the model has to carry.
What this changes in practice
Once an application depends on LLMs, tokenizing a string becomes a resource allocation problem.
A few patterns hold up in production:
- Prompt templates should stay tight. Repeated boilerplate adds cost on every request.
- Retrieved context has to justify its tokens. Long, weakly relevant passages are expensive clutter.
- Language mix changes unit economics. The same feature can cost more in one market than another.
- Preprocessing still earns its keep. Removing duplicated text, broken markup, and OCR noise lowers waste before the model tokenizer ever runs.
This is the gap a lot of tokenization tutorials miss. Traditional tokenization asks, “What are the useful text units for my application?” LLM tokenization adds a second question: “How many billable model tokens will this input become?” In modern systems, both matter.
A simple operating model
Keep the two layers separate:
Mixing them up causes avoidable mistakes. A regex tokenizer can be perfect for indexing and still tell you nothing about API cost. A model tokenizer can estimate spend accurately and still be useless for extracting business entities or search terms.
Use each one for its actual job. That is how you keep text pipelines understandable, model requests efficient, and token bills under control.
Token Accounting Observability and Streaming
A token spike usually shows up first as a product problem, not a tokenizer problem. A request starts timing out, a chat answer gets cut off, or the monthly bill jumps after a prompt change that looked harmless in review. That is why production LLM work needs token accounting, not just tokenization.
Count before you send
Preflight counting gives you a control point before the provider rejects a request or turns an expensive prompt into an even more expensive completion. In practice, that helps with three things:
- Context limits: Trim, chunk, or summarize before the request fails.
- Cost control: Estimate whether a request is cheap enough to send as-is.
- Model routing: Send short, simple jobs to smaller models and reserve larger context windows for work that needs them.
The important detail is that LLM tokens are not the same units you used earlier for regex tokenization, search indexing, or entity extraction. A clean word split can still miss the billing impact of repeated boilerplate, JSON wrappers, chat role metadata, or multilingual text that expands differently under a model tokenizer.
I usually treat preflight counts as admission control. If the request is already near the limit before retrieval or tool output is added, the system should compress context or drop lower-value text early. Waiting until the API call fails is slow and expensive.
Observe actual token usage
Estimates are useful. Actual usage is what supports decisions.
Provider-reported token counts tell you whether your assumptions were right and whether a change in prompts, retrieval, or output format shifted cost in ways the team did not expect. They also help separate two very different problems: oversized inputs and overly long completions.
Useful observability usually includes:
- Prompt and completion tokens: Identify whether spend comes from what you send or what the model generates.
- Latency per request: More tokens often increase time, but provider load, tool calls, and network behavior matter too.
- Prompt version, model, and route: Tie token changes to a specific template or serving path.
- Feature or endpoint name: Compare chat, summarization, extraction, and agent flows on cost and speed.
- Truncation and retry events: Catch hidden waste from requests that fail, restart, or exceed limits.
Without that data, prompt work turns into opinion. With it, trade-offs get concrete. A longer system prompt might improve answer quality enough to justify its cost. A retrieval step might add a lot of tokens and very little relevance. Both cases happen.
Streaming changes control flow
Streaming improves perceived responsiveness, but the bigger engineering benefit is observability during generation. You can measure time to first token, detect slow starts, and decide whether to stop a response that is clearly off track.
That matters in chat and copilot products, where users judge speed by when text starts arriving, not only by total completion time.
Streaming also gives the application a chance to intervene. If a completion is rambling, repeating itself, or heading toward an unwanted format, the client can cancel early and cap output tokens. That does not fix a bad prompt, but it does limit waste and shorten the path to a better retry strategy.
A practical operating model
A production baseline usually looks like this:
Teams that manage token costs well do one extra thing. They tie token usage back to product behavior. Which prompt version increased retrieval size. Which customer workflow triggers the longest completions. Which language mix raises per-request cost. That is the point where traditional string handling and modern LLM token accounting finally meet. You still need good text processing, but now every token also has a performance and budget consequence.
Frequently Asked Questions about String Tokenization
What's the difference between a word and a token
A word is a human language concept. A token is whatever unit your system chooses to operate on.
Sometimes those match. Often they don't.
In a regex tokenizer, state-of-the-art might be one token or several depending on your rule. In an LLM tokenizer, a single visible word may become multiple subword tokens. That's normal. The tokenizer is optimizing for the system's needs, not for dictionary purity.
How should I handle Unicode and emojis
Don't assume ASCII unless your input is tightly controlled.
For ordinary application text, Unicode-aware regex or ICU-based tooling is safer than hand-written character classes that only recognize English letters. For model-facing text, use the model's own tokenizer whenever possible. LLM tokenizers are designed to encode arbitrary strings and decode them back exactly, which is one reason they handle mixed text, symbols, and unusual characters better than simplistic split rules.
If your app ingests multilingual content, test with real examples instead of synthetic English-only sentences. That's where hidden tokenization bugs usually show up first.
Which tokenizer should I use for my project
Use this rule of thumb:
- Simple split: Good for controlled delimiters and internal formats.
- Regex tokenizer: Good when you need explicit rules around punctuation, apostrophes, or domain-specific patterns.
- NLP library tokenizer: Good when input is messy, multilingual, or part of a larger language pipeline.
- Model tokenizer: Required when you care about LLM context size, prompt packing, or API billing.
A quick decision table helps:
The mistake isn't choosing a simple tool. The mistake is keeping a simple tool after the text has become complex.
If you're building AI features in production, Supagen provides the layer many organizations end up rebuilding by hand: prompt management, model routing, observability, and per-call visibility into tokens, latency, I/O, and cost. This makes it much easier to ship fast, see where token usage is going, and improve your AI stack without hardcoded prompt logic spread across the app.