Streaming Source Code: A Practical How-To Guide

You're probably in the middle of this right now. A product manager wants live progress updates, your AI feature needs token-by-token output, support wants build logs in real time, and someone on the team says “just stream it” like that's a small implementation detail.
It isn't. Streaming source code changes how you design handlers, how you think about retries, how you test failures, and how you debug production incidents. The first demo usually works fast. The expensive part shows up later, when clients reconnect mid-response, messages arrive twice, logs get split across chunks, and nobody can explain why one provider feels slower even though your code didn't change.
The good news is that the core ideas are stable. The bad news is that most tutorials stop at the happy path. They show how to open a socket or emit chunks, but they skip the lifecycle work that makes streaming reliable: protocol choice, state handling, backpressure, schema discipline, observability, and operational cleanup.
Table of Contents
- Why Streaming Matters for Modern Apps
- Comparing Core Streaming Protocols
- Implementing Streaming with Source Code Examples
- Productionizing Your Streams Deployment and Debugging
- Optimizing Stream Performance and Cost
- Unifying Stream Observability with Supagen
Why Streaming Matters for Modern Apps
A user clicks “Generate,” and nothing happens for eight seconds except a spinner. In production, that gap feels longer than it sounds. People retry, open duplicate tabs, assume the job failed, or abandon the flow entirely. Streaming fixes that by turning long waits into visible progress: first tokens, partial rows, build logs, job state changes, and incremental results that prove the system is alive.
That change is not cosmetic. It affects product behavior, backend design, deployment choices, and how support teams debug failures at 2 a.m. The hard part is not getting bytes to move. The hard part is deciding what can be emitted early, how clients recover after disconnects, how partial failures surface, and how to observe all of it without stitching together five different tools.
Real-time expectations changed the baseline
Users now expect systems to respond before the full job is done. Chat interfaces are the obvious example, but the same expectation shows up in code generation, ETL jobs, dashboards, CI logs, transcription, and any workflow that takes more than a second or two. Silence reads as failure.
The data side pushes in the same direction. Streaming algorithms became practical because some workloads are too large, too continuous, or too latency-sensitive for “load everything, then process.” IDC projected that global data creation would reach 181 zettabytes in 2025 in its Data Age 2025 research summary, as cited by Statista's coverage of global data creation volume. The same Wikipedia reference states that 60% of Fortune 500 companies use streaming algorithms for real-time analytics as of 2024, citing Gartner's market view on streaming data and analytics adoption.
Those numbers matter because they match what shows up in real systems. Teams are no longer streaming only for trading platforms or telecom infrastructure. They are streaming because users expect feedback fast, and because batch boundaries keep disappearing.
Streaming is a data handling pattern, not just a transport
A lot of teams reduce streaming source code to a protocol choice. That is usually the easy part.
The real design work starts earlier. A stream needs an event model, ordering rules, resumability, timeout behavior, cancellation handling, and a clear definition of completion. If those decisions are missing, the implementation usually degrades into buffered pseudo-streaming where the server does all the work upfront and dribbles it out at the end.
Two layers matter:
- Transport: SSE, WebSockets, gRPC streaming, and provider-specific LLM streams determine how data gets from one process to another.
- Application logic: iterators, chunk boundaries, event IDs, checkpoints, retries, and rolling state determine whether partial output is safe to emit.
A practical rule helps here. If a feature needs progress updates, partial output, or long-lived state changes, define the stream contract before writing the final response shape.
That is also where hidden costs start to show up. Every stream creates operational questions: how many concurrent connections can one node hold, what proxies buffer by default, what happens after a reconnect, how backpressure is handled, which events are safe to replay, and how logs from the transport layer line up with application events. Tutorials usually stop at “hello world” code. Production systems fail in the edges around that code.
This is why a unified backend matters. Without one, teams often split streaming transport, job orchestration, state storage, retries, metrics, and debugging across separate services. The feature works, but the operating cost climbs fast. A backend that keeps those concerns connected makes streaming easier to ship and much easier to reason about once real traffic hits it.
Comparing Core Streaming Protocols
The protocol decision shouldn't start with hype. It should start with constraints: browser or backend, one-way or two-way, human-facing or machine-facing, low setup overhead or strict contracts.
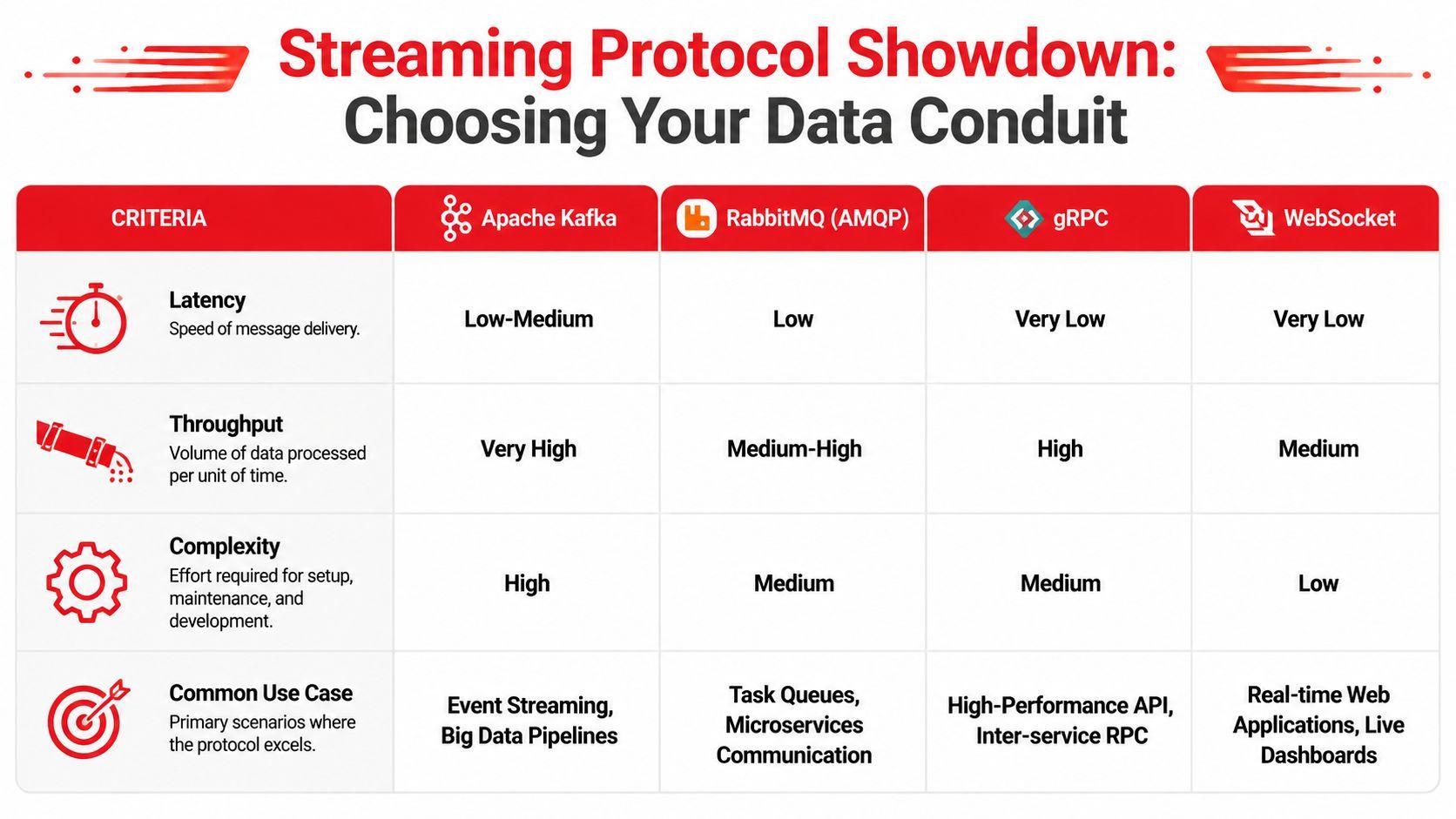
What each option is actually good at
Here's the short version I'd use in a design review.
SSE is still underrated. If the client only needs updates from the server, SSE is often the least painful choice. It rides on standard HTTP semantics, works well with reverse proxies when configured correctly, and gives you a straightforward event model. For notification feeds, job progress, build logs, and token streams to browsers, it's usually enough.
WebSockets are what teams reach for when they hear “real time.” Sometimes that's right. Presence, multiplayer editing, and bidirectional chat controls all benefit from a persistent full-duplex channel. The trade-off is that your backend now owns a session model whether you intended to or not. Connection lifecycle bugs show up quickly.
A lot of systems don't need bidirectional streaming. They need reliable server push. Choosing WebSockets too early often buys flexibility you never use and complexity you definitely will.
gRPC streaming shines inside a backend where you control both ends. It gives you explicit contracts, generated clients, and a clean model for request streams, response streams, or both. It's especially good when one service is feeding another service continuously and schema drift needs to be tightly managed.
LLM-specific output streaming is common now, but it comes with a trap. Teams wire their frontend directly to a provider's chunk format, token event shape, finish reason, and error conventions. That's fast for a prototype. It becomes expensive once you add fallbacks, model switching, multimodal output, or audit requirements.
A practical selection checklist
Use this when you need a decision that survives production:
- Choose SSE when the browser only needs server updates and you want simple operational behavior.
- Choose WebSockets when the client and server both need to speak continuously during the same session.
- Choose gRPC streaming when backend services need typed contracts and high-performance internal communication.
- Choose provider-native LLM streaming carefully if speed matters more than portability. Wrap it behind your own event contract early.
A useful heuristic is to pick the simplest protocol that matches your interaction pattern. Streaming source code gets harder when transport semantics and business semantics are mixed together. Keep those separate, and switching later stays possible.
Implementing Streaming with Source Code Examples
Working examples matter because streaming looks more complex than it is. The mechanics are usually small. The design decisions around them are the hard part.
SSE for one-way browser updates
For browser clients, this is the easiest place to start.
Python server with FastAPI
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
import asyncio
import json
app = FastAPI()
async def event_stream():
for i in range(5):
payload = {"type": "progress", "step": i + 1}
yield f"data: {json.dumps(payload)}\n\n"
await asyncio.sleep(1)
yield f"data: {json.dumps({'type': 'done'})}\n\n"
@app.get("/stream")
async def stream():
return StreamingResponse(event_stream(), media_type="text/event-stream")Browser client
<script>
const events = new EventSource("/stream");
events.onmessage = (event) => {
const data = JSON.parse(event.data);
console.log("event:", data);
if (data.type === "done") {
events.close();
}
};
events.onerror = () => {
console.error("stream error");
events.close();
};
</script>This pattern is good for progress updates, logs, AI token output, and status feeds. The gotcha is buffering. If a proxy or middleware buffers the response, your stream “works” but arrives in clumps. When that happens, engineers often blame the client first. Check the network path before rewriting the frontend.
WebSockets for bidirectional sessions
If the client needs to send and receive events continuously, use WebSockets.
Node server with ws
const WebSocket = require("ws");
const server = new WebSocket.Server({ port: 8080 });
server.on("connection", (socket) => {
socket.send(JSON.stringify({ type: "connected" }));
socket.on("message", (message) => {
const incoming = JSON.parse(message.toString());
if (incoming.type === "ping") {
socket.send(JSON.stringify({ type: "pong" }));
}
if (incoming.type === "chat") {
socket.send(JSON.stringify({
type: "chat_ack",
message: incoming.message
}));
}
});
socket.on("close", () => {
console.log("client disconnected");
});
});Browser client
<script>
const socket = new WebSocket("ws://localhost:8080");
socket.onopen = () => {
socket.send(JSON.stringify({ type: "ping" }));
socket.send(JSON.stringify({ type: "chat", message: "hello" }));
};
socket.onmessage = (event) => {
console.log("received:", JSON.parse(event.data));
};
socket.onclose = () => {
console.log("socket closed");
};
</script>This is enough to prove the transport, but not enough for a real app. In production, define message types explicitly, include event IDs where replay matters, and separate control messages from business payloads. Don't let arbitrary JSON become your long-term protocol.
gRPC streaming for service-to-service traffic
For internal systems, gRPC helps when both sides are under your control.
A simple .proto contract might look like this:
syntax = "proto3";
service LogStream {
rpc WatchLogs (LogRequest) returns (stream LogEvent);
}
message LogRequest {
string job_id = 1;
}
message LogEvent {
string line = 1;
bool done = 2;
}Python server shape
class LogStreamServicer:
def WatchLogs(self, request, context):
for line in ["starting", "running", "finishing"]:
yield LogEvent(line=line, done=False)
yield LogEvent(line="complete", done=True)The main practical benefit here isn't just speed. It's contract clarity. When teams move from ad hoc JSON streams to typed messages, debugging gets easier because everyone agrees on message shape and termination behavior.
LLM token streaming without coupling your UI to a provider
Most AI apps start by streaming raw provider events into the browser. That's fast, but it couples your app to one vendor's event schema. A better pattern is to normalize provider output on the server and expose your own event format to the client.
A minimal server contract might emit events like:
{ "type": "token", "text": "Hel" }
{ "type": "token", "text": "lo" }
{ "type": "usage", "input": "...", "output": "..." }
{ "type": "done" }That gives you room to change providers later without rewriting the UI. It also lets you insert moderation, fallback handling, or partial validation before the user sees output.
Keep your frontend dependent on your stream contract, not on a model vendor's chunk format.
For streaming source code, that one architectural choice saves a lot of cleanup later. It also makes testing easier because you can replay recorded event sequences against the UI without needing a live provider connection.
A final implementation habit that pays off across all four approaches is using generators, iterators, or async streams in your application code. They mirror the shape of the problem. Instead of building a giant string and returning it at the end, your code yields meaningful units of work as they happen.
Productionizing Your Streams Deployment and Debugging
A stream can look perfect in staging and still fail in the first hour of production. The failure usually starts somewhere mundane. A phone drops from Wi-Fi to LTE, a worker restarts halfway through flushing state, or one slow consumer turns a small backlog into a memory problem.
Production work is less about picking a protocol and more about deciding what happens during retries, restarts, lag, and partial failure. That is where streaming projects get expensive. The code path that streams bytes to a client is often the easy part. The hard part is keeping delivery semantics, state, logs, and alerts aligned across the app, broker, workers, and client.
Exactly-once is mostly an application design problem
Exactly-once behavior depends on discipline across the whole path. The transport can help, but it cannot rescue a handler that performs side effects twice or loses its place during recovery.
A practical baseline looks like this:
- Make writes idempotent. Use stable event IDs. Treat duplicate delivery as normal operating behavior.
- Persist progress. Offsets, checkpoints, or transaction markers need to survive restarts and deploys.
- Test failure on purpose. Kill consumers mid-stream, interrupt network paths, and confirm that recovery does what you think it does.
Teams often chase exactly-once labels in infrastructure before they have those three pieces in place. That usually ends in false confidence. If the business action behind the stream cannot be replayed safely, the system is still fragile.
Checkpointing is a good example. Frequent checkpoints improve recovery point objectives, but they also add I/O overhead, increase storage churn, and can lengthen recovery if state has grown without anyone noticing. The right interval depends on state size, write rate, and how much duplicate work the application can tolerate after a crash. There is no default setting that stays correct as traffic changes.
What usually breaks first
Three failure modes show up repeatedly in production systems.
- Dropped connections: browser tabs sleep, proxies time out idle connections, and mobile networks reset long-lived sessions.
- Duplicate delivery: retries happen at every layer. Brokers retry. clients retry. workers restart.
- State growth: replay buffers, session maps, and per-stream metadata expand until latency spikes or a process runs out of memory.
Build every consumer with that assumption set.
This matters even for simple SSE endpoints. If a client reconnects and asks for missed events, the server needs a clear answer. Support replay with stable IDs and bounded history, or state plainly that the stream is ephemeral and the client must re-request the full result. Incidents get ugly when the frontend assumes resumability and the backend only offers best-effort delivery.
Another common miss is logging streams as if they were ordinary request-response calls. That is not enough for debugging partial output. For streaming source code, each logical operation should emit structured records that include a request ID, a stream ID, chunk sequence, event type, timing, and a final termination reason such as completed, cancelled, timed_out, or upstream_error. Without that, postmortems turn into guesswork.
Deployment and debugging gotchas that docs skip
Rolling deploys are a frequent source of broken streams. If a new version drains connections differently, changes event ordering, or starts emitting a slightly different payload shape, reconnect paths break first. Backward-compatible stream contracts matter just as much as backward-compatible APIs.
Backpressure is another place where simple demos mislead people. A producer that can generate data faster than the network or consumer can accept it needs a policy. Buffering everything in memory works until it does not. In practice, choose one of four behaviors and make it explicit: slow the producer, drop old data, drop new data, or terminate the stream. Every option has product consequences, and pretending you can avoid the choice usually leads to the worst one being made accidentally.
This is also where a unified backend starts paying for itself. Separate tools for app logs, queue lag, worker metrics, and client errors make incident response slower because the same failure is split across four dashboards with four different identifiers. The better setup is one stream-centric view that ties together connection lifecycle, broker progress, handler state, and user-visible output. That cuts debugging time far more than another round of protocol tuning.
Here's a compact preflight checklist I use before shipping any stream:
- Connection policy: timeouts, heartbeats, retry windows, and drain behavior during deploys
- Delivery target: at-most-once, at-least-once, or exactly-once at the business-operation level
- Replay policy: resumable with IDs and retention, or intentionally non-resumable
- Observability fields: request ID, stream ID, chunk index, lag, termination status, and upstream dependency ID
- Backpressure behavior: buffer, shed, throttle, or fail fast
- Runbooks: what on-call does when lag grows, checkpoints fail, or reconnect storms start
For a deeper walkthrough of production trade-offs, this talk covers reliability, deployment behavior, and debugging patterns for real streaming systems:
Optimizing Stream Performance and Cost
A stream can be correct, stable, and still cost far more than it should. That usually happens when a team tunes the protocol or runtime before checking where the money goes: state growth, skewed partitions, serialization overhead, sink pressure, and downstream fan-out.
Micro-batch versus true streaming
The runtime choice sets your cost floor. XenonStack's stream analytics benchmarks report Apache Flink at 5M tuples/sec on a c5.4xlarge AWS instance, compared with Spark Streaming at 2M, and the same benchmark summary also notes that schema evolution failures affect 30% of production deployments.
Benchmarks like that are useful, but they are easy to misuse. Flink often wins when the workload depends on event-time processing, long-lived state, and lower per-record latency. Spark Streaming can still be the better deal for teams that already run Spark, can tolerate short processing intervals, and care more about operational familiarity than shaving off every second of delay.
Use the simpler runtime if the product can tolerate it.
A quick filter helps:
The expensive mistake is building for sub-second latency when the user only checks the result every 30 seconds. The opposite mistake is forcing an interactive product onto micro-batches and then paying for retries, buffering, and unhappy users because the system misses timing expectations.
The tuning work that actually pays off
The largest gains usually come from operational details, not exotic optimizations.
- Partition with intent: Key selection decides whether throughput stays flat or one worker gets crushed. A bad key creates hot partitions, uneven checkpoint times, and ugly tail latency.
- Control state growth: TTLs, window strategy, compaction, and cleanup jobs need explicit review. Unbounded state becomes bigger instances, slower recoveries, and expensive storage.
- Treat schemas as production assets: Use Avro with a schema registry if your stack supports it. Informal JSON compatibility breaks during staggered deploys, consumer lag, or partial rollbacks.
- Benchmark end-to-end: Operator benchmarks miss the actual bottlenecks. Serialization, network hops, sink write limits, and backpressure often dominate total latency.
I have seen teams spend weeks tuning operator code and ignore the fact that the sink was rate-limited and forcing retries across the whole pipeline. That kind of miss is common in streaming systems because the visible symptom appears far away from the actual bottleneck.
Cost work also changes once the stream leaves the data platform and reaches product features. For AI workloads, fast first-byte latency can hide expensive behavior underneath. A token stream may feel responsive while triggering multiple retrieval calls, fallback model requests, and duplicate writes for audit or replay. Measure cost per completed user task, not just throughput or first output time.
This is also where architecture starts to matter more than isolated component tuning. Separate brokers, workers, stream handlers, tracing tools, and cost dashboards make optimization slower because each team sees only its own slice. A unified backend cuts that overhead. It lets you trace one stream across ingestion, processing, delivery, and spend, which is often the difference between identifying the cost driver in an hour or arguing about the wrong graph for a week.
Unifying Stream Observability with Supagen
A stream looks healthy in staging. Then production traffic hits, one provider slows down, fallback starts firing, and support reports that users saw partial output, duplicated chunks, or a response from the wrong model. The hard part is no longer transport. It is reconstructing what happened across routing, prompts, retries, and delivery after the fact.
That problem gets worse as teams mix browser streams, async workers, and LLM output in the same feature. A browser console shows only the client side. Provider dashboards show only their own requests. Application logs usually miss token timing, fallback decisions, and prompt versions unless someone added that instrumentation up front.
The operational questions are predictable:
- Which provider served this request?
- What condition triggered fallback or retry?
- Which chunks map to a single user action or trace?
- Did latency come from the model, the network path, or our orchestration code?
- How much did this streamed response cost, including failed attempts?
If those answers live in four different systems, debugging gets slow and ownership gets blurry. I have seen teams argue over whether a stream bug belonged to frontend code, the model vendor, or queue workers, when the actual issue was a timeout threshold that forced a fallback too early.
A unified backend changes the day-to-day work because routing, logging, prompt history, and cost data sit in one place instead of being stitched together from vendor tools and custom traces.
In practice, that gives teams a few concrete advantages:
- Provider routing becomes configurable. You can add a fallback path or change model priority without rewriting stream handlers in every service.
- Prompt and model changes become traceable. A bad prompt release stops being guesswork because you can tie output quality and latency back to a version.
- Per-request logs become useful during incidents. You can inspect timing, inputs, outputs, retries, and failures for one stream instead of reading generic error lines.
- Different response types stay under one control plane. Text, image, audio, and structured outputs do not need separate operational playbooks.
There is a trade-off. A unified layer adds another dependency and another place to model your request flow. If the platform hides too much, debugging can become harder, not easier. The good implementations avoid that by preserving raw request details, provider-specific errors, and request IDs you can still correlate with the rest of your stack.
That is the gap many streaming tutorials skip. Shipping a demo stream is straightforward. Running streamed features in production, with fallback logic, cost controls, and incident debugging, is where teams usually pay the complexity tax.
If you're building AI features that need streaming, routing, prompt management, and production-grade observability without hardcoding everything into your app, Supagen is worth a look. It gives you one backend for model orchestration, per-call logs, cost visibility, prompt versioning, and provider fallbacks, so you can ship faster and debug streaming behavior without redeploying your whole stack.
Powered by Outrank tool