AI Health Monitoring: A Production-Ready Guide

Your team probably has a model demo that looks promising already. A smartwatch stream comes in, an LSTM flags a risky pattern, and a dashboard lights up with an alert that seems clinically useful.
Then production starts asking harder questions. What happens when devices send inconsistent timestamps, patients stop wearing the watch overnight, Bluetooth sync lags for hours, and a clinician gets an alert with no context they can trust? In ai health monitoring, the algorithm is rarely the first thing that breaks. Pipelines, validation, observability, escalation logic, and governance usually break first.
Table of Contents
- The Challenge Beyond the Algorithm
- Real-World Applications of AI Health Monitoring
- The Anatomy of an AI Health Monitoring System
- End-to-End Architecture and Deployment Considerations
- Navigating Privacy Safety and Regulation
- An Implementation Checklist for Production Systems
- Getting Started and Future Trends
The Challenge Beyond the Algorithm
A common starting point is simple. The product team wants early cardiac distress alerts from smartwatch data. Data science can already show good offline performance on historical samples, and everyone assumes the hard part is done.
It isn't. The real work starts when the feature has to ingest noisy device streams continuously, compute features reliably, run inference with predictable latency, and deliver an alert that a care team can interpret and act on. In practice, ai health monitoring succeeds or fails on system behavior under messy conditions, not on a clean notebook chart.
The industry pattern matches that reality. A 2025 survey on AI adoption in healthcare organizations found that 90% had deployed AI for imaging, 53% reported a high degree of success for AI in clinical documentation, and only 19% reported a high degree of success for AI in clinical diagnosis. That gap matters. Operational use cases are easier to control, easier to evaluate, and easier to fit into workflow. Diagnostic use cases demand stronger validation, tighter safety boundaries, and much better post-deployment monitoring.
Why notebook success doesn't survive contact with production
Teams usually underestimate four things:
- Data instability: Wearables drop samples, resample without notification, and arrive late.
- Context loss: A risk score without recent trend data, confidence, and signal quality isn't useful.
- Workflow friction: If alerts land in the wrong queue or require extra clicks, clinicians ignore them.
- Runtime drift: Patient behavior, devices, and care settings change after launch.
Practical rule: If your system can't explain why it generated an alert and what data supported it, it isn't ready for clinical workflow.
The hardest lesson is that model quality is only one dependency in a chain of dependencies. If ingestion, feature generation, identity matching, alert routing, and feedback capture aren't production-grade, the end result still feels unreliable to clinicians and patients.
Real-World Applications of AI Health Monitoring
The strongest ai health monitoring products don't try to replace clinicians. They extend observation beyond the clinic and make changes visible sooner.
Market momentum explains why so many teams are building here. An industry summary of healthcare AI and remote patient monitoring adoption reported that the global remote patient monitoring system market was valued at USD 5.2 billion in 2023, with a projected 18.6% CAGR from 2024 to 2030. The same source noted that 85% of healthcare leaders said they were investing in or planning to invest in generative AI over the next three years. This is no longer a side experiment. It's infrastructure planning.
Remote monitoring in daily care
A patient leaves the hospital after a cardiac event. Instead of relying only on scheduled follow-ups, the care team gets a continuous stream of heart rate, oxygen saturation, activity, and sleep-adjacent signals from a wearable and home devices.
The useful part isn't the dashboard. It's the operational loop. Data has to arrive reliably, baseline behavior has to be established for that patient, and the system has to separate transient noise from a meaningful deviation. Good remote monitoring products don't fire on every anomaly. They rank events by urgency and attach enough context for a nurse or physician to decide what to do next.
Chronic disease management
Chronic care is where continuous monitoring becomes more than passive recording. For diabetes, hypertension, or heart failure workflows, the important job is trend detection. Teams aren't just watching single measurements. They're watching direction, variability, adherence patterns, and combinations of changes that suggest deterioration.
That changes the product design. Instead of one threshold, you need patient-specific windows, missing-data handling, and escalation rules that account for overnight gaps, medication changes, and uneven device use.
A short explainer is useful here:
Clinical decision support
In hospital settings, ai health monitoring works best as a co-pilot. It can flag patterns across telemetry, nursing observations, and streaming vitals that a busy unit may not spot early enough.
That doesn't mean full autonomy. It means surfacing suspicious change with timing, trend, confidence, and recent supporting signals. A system that only says "high risk" is hard to trust. A system that shows the last several hours of deviation, identifies the sensor inputs involved, and routes the alert to the right team has a much better chance of being used.
The win isn't that AI sees everything. The win is that it helps the right person see the right change before the situation becomes urgent.
The Anatomy of an AI Health Monitoring System
AI health monitoring is frequently discussed as if the model is the product. It isn't. The product is the combination of inputs, feature pipelines, inference logic, and operational outputs.
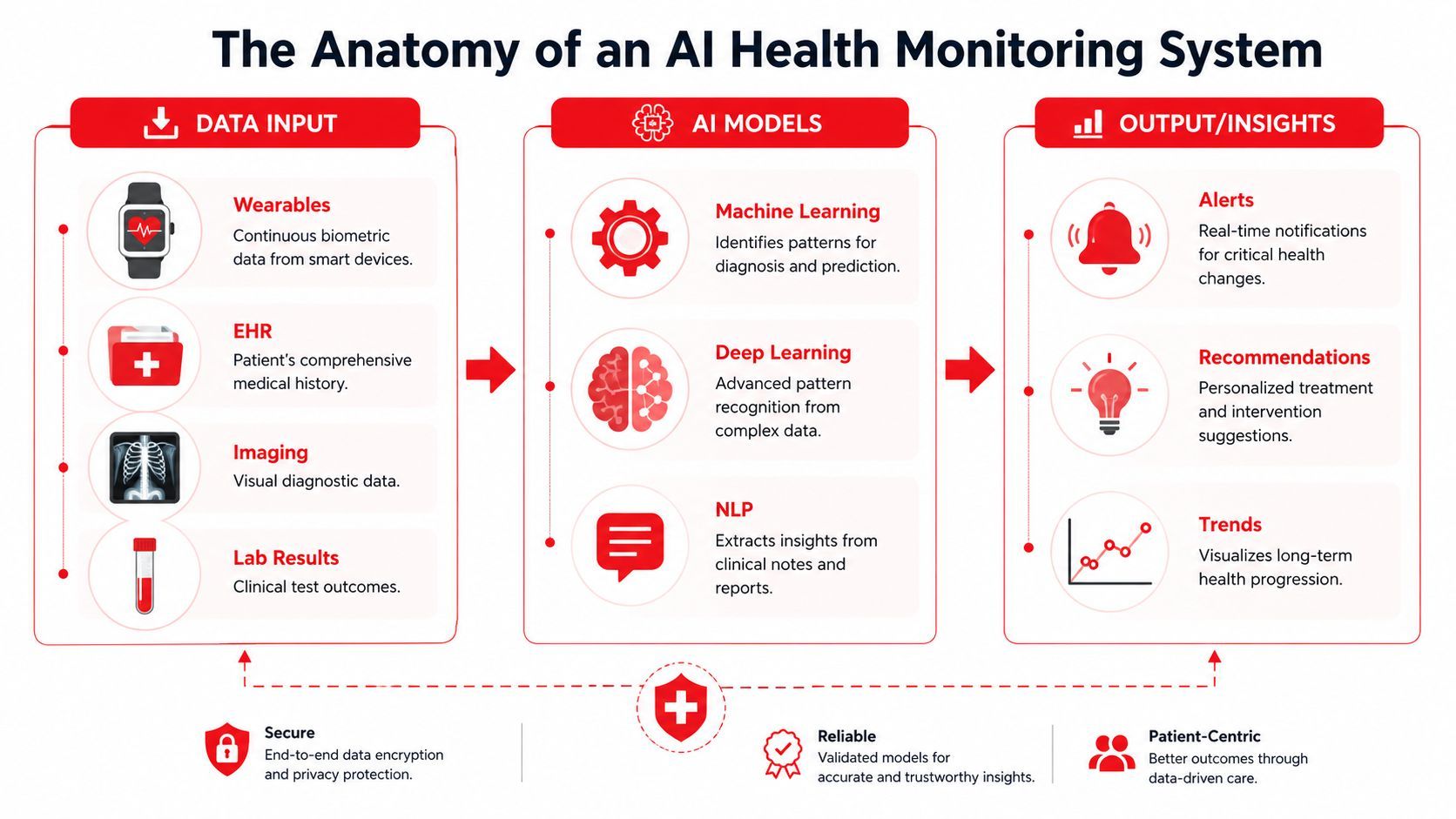
Data is the raw material
Think of the system as ingredients and recipe. The ingredients are the signals. If they arrive incomplete, poorly aligned, or without patient context, even a strong model will underperform.
Common inputs include:
The strongest systems use more than one source of truth. Continuous physiology is powerful, but it becomes much more useful when paired with patient history and care context.
Model choice follows signal shape
Time-series physiological data needs models that can deal with sequential change, not just static snapshots. According to this technical overview of AI-powered health monitoring systems, teams commonly use LSTM and XGBoost models trained on ECG and physiological streams to detect anomalies such as heart rate variability deviations and fluid retention before clinical events. The same source says these models can achieve over 95% sensitivity and specificity in identifying arrhythmias, and that early risk prediction has been shown to reduce hospital readmissions by up to 30% in chronic care cohorts.
That sounds impressive, but the engineering implication matters more than the headline. LSTMs help when temporal order and sequence history matter. XGBoost often works well when you've already transformed streams into effective summary features such as rolling variance, trend slope, time-above-threshold, or heart rate variability metrics. In real systems, teams often use both styles at different layers.
A practical split looks like this:
- Sequence models: Useful when raw or lightly processed signal order contains the signal you care about.
- Tree-based models: Useful when you trust your feature engineering and want fast, interpretable serving.
- Fusion layers: Useful when one model handles physiology and another brings in clinical context from records.
Outputs must be operationally useful
A model output shouldn't end at a probability score. Production systems need outputs that support action:
- Risk state: Normal, increased, urgent, or review-needed.
- Supporting evidence: Which signals moved, over what time window.
- Confidence and quality markers: Whether the incoming signal quality was good enough to trust.
- Recommended route: Notify clinician, request repeat measurement, or log for trend review.
A good health model doesn't just predict. It packages the prediction so another system, or a human, can do something safe with it.
That's the line between interesting AI and deployable AI.
End-to-End Architecture and Deployment Considerations
A production ai health monitoring system is a chain. If one link is weak, the whole product becomes unreliable.
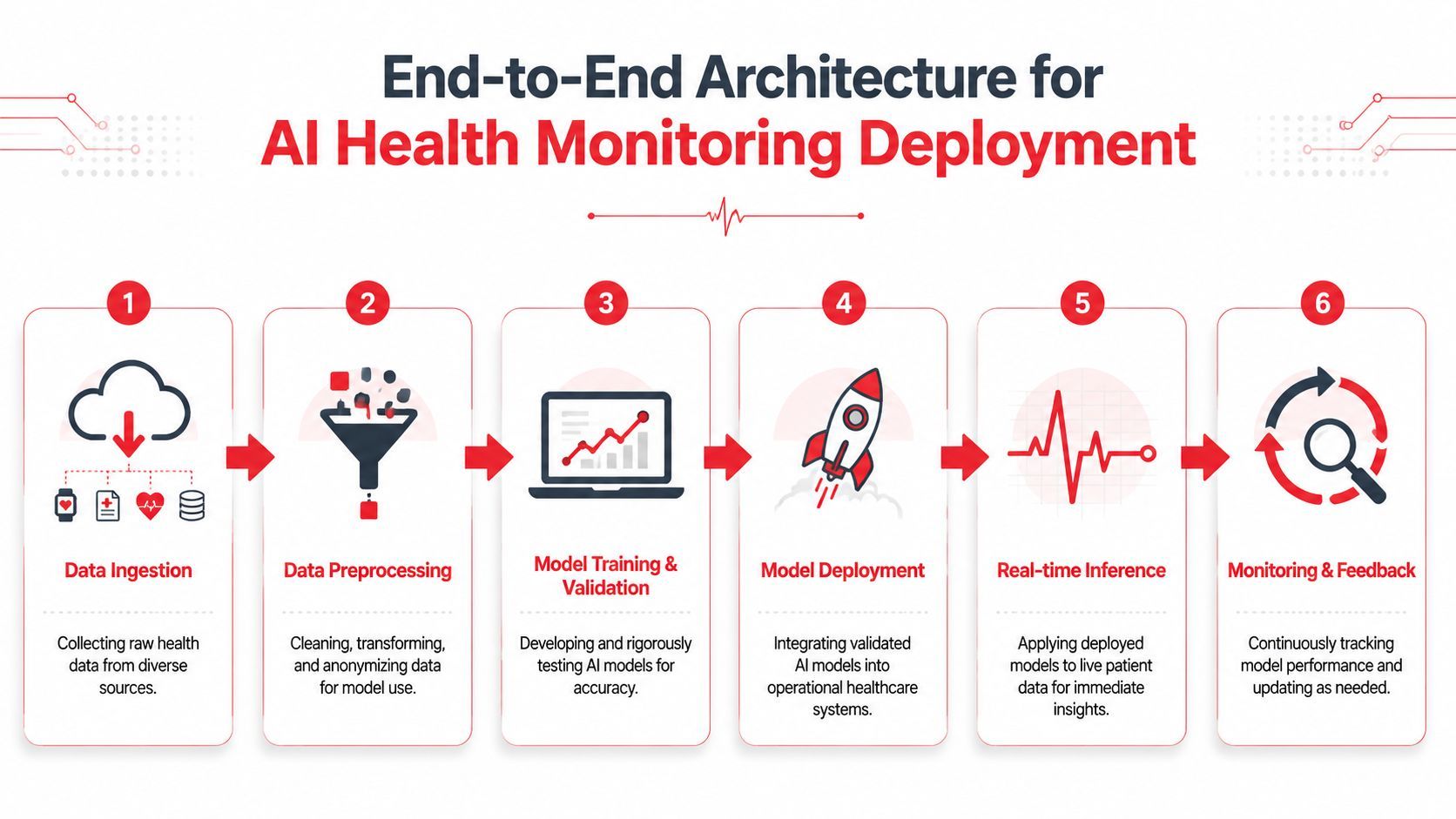
From sensor to storage
Start with the path of a single event. A wearable records a measurement. The device app batches or streams it upstream. The backend authenticates the sender, normalizes timestamps, checks schema validity, and maps the record to the right patient identity. Only then should it enter your feature pipeline.
That first stage breaks more often than teams expect. Devices buffer offline. Mobile apps resend duplicate events. Timestamps come from device local time instead of server time. If your ingestion layer doesn't deduplicate and preserve provenance, you'll train on one reality and serve on another.
A dependable ingestion path usually needs:
- Device-aware adapters that normalize vendor-specific payloads.
- Idempotent write logic so retransmissions don't create fake events.
- Signal quality metadata captured alongside the measurement.
- Audit trails for every transformation.
Inference is only one stage
After ingestion comes preprocessing. During this stage, raw stream data gets cleaned, windowed, anonymized where appropriate, and transformed into features or model-ready tensors. In many systems, this stage determines reliability more than the model itself.
Serving then has to decide whether inference happens in near real time, on schedule, or in a hybrid mode. Real-time alerts sound attractive, but some workflows work better with short aggregation windows because they suppress noise and make alerts more clinically meaningful.
Common deployment choices and trade-offs:
Versioning is another frequent pain point. You need model version control, feature version control, and alert-policy version control. If you only version the model artifact, you won't be able to explain why behavior changed after a release.
Observability has to include clinical reality
Traditional MLOps dashboards cover latency, throughput, errors, and drift. Health systems need more than that. You also need to know whether alerts were clinically useful, whether specific clinics see different failure patterns, and whether performance degrades for subgroups after launch.
A review on AI implementation safety and fairness in healthcare emphasizes that average model accuracy can hide clinically significant failures in specific populations and recommends subgroup validation, uncertainty reporting, and ongoing post-launch monitoring. That's one of the most important operational truths in this space.
What to monitor in production:
- System metrics: Queue delay, failed ingestions, processing latency, retry rates.
- Model metrics: Input drift, confidence distribution, score stability, fallback rates.
- Clinical metrics: Alert acknowledgment, override patterns, escalation outcomes, missed-event reviews.
- Equity checks: Performance by care setting, device type, and patient subgroup.
If you only monitor aggregate accuracy, you'll miss the exact failures that create safety risk.
The mature teams close the loop. They collect clinician feedback on alerts, feed reviewed outcomes back into validation, and treat post-launch evaluation as part of the product, not as a one-time compliance exercise.
Navigating Privacy Safety and Regulation
In ai health monitoring, privacy and safety aren't review gates at the end. They shape architecture decisions from day one.
Privacy starts at system design
The safest data isn't the data you promise to protect later. It's the data you never collect unless you need it. That principle changes how you design event schemas, logs, dashboards, and support tooling.
A practical privacy posture usually includes:
- Data minimization: Collect only the fields required for monitoring, triage, and audit.
- Role-based access: Clinicians, support staff, and engineers shouldn't see the same data.
- De-identification where possible: Training and analytics environments should avoid direct identifiers when they aren't necessary.
- Retention rules: Continuous monitoring creates massive histories. Teams need clear deletion and archival policies.
The mistake I see often is observability tooling that leaks sensitive context into logs. A model endpoint may be secure, but a debugging console full of raw patient payloads still creates risk.
Safety needs explicit failure modes
Safety work starts by assuming the system will fail sometimes. Sensors will degrade. Models will encounter unfamiliar data. Integrations will lag. The question is whether the failure is detectable and contained.
Useful safeguards include a confidence threshold, signal-quality gating, fallback rules when the model can't score safely, and escalation paths that distinguish urgent action from clinician review. Teams also need a documented boundary around what the system does and does not decide autonomously.
That boundary matters for regulatory posture too. If a product is influencing clinical decisions, teams need to think carefully about software classification, validation evidence, update control, and change management. Even when a feature is framed as decision support, you still need disciplined release processes and traceable evidence for why the output should be trusted.
Equity is an engineering requirement
Equity gets discussed as policy, but it shows up as implementation detail. Device compatibility, language support, onboarding burden, connectivity assumptions, and training quality all affect who benefits.
A California Health Care Foundation discussion of AI adoption in underserved communities argues that equitable adoption requires targeted funding, staff training, and community involvement, and warns that AI can widen disparities if those conditions are missing. That's highly relevant for monitoring systems. A tool that works in a well-resourced cardiology program may add burden in a rural clinic if integration and staffing assumptions don't hold.
A good design review should ask:
- Who has to maintain this workflow every day?
- What happens in clinics with limited technical support?
- Does the model depend on data quality that some patient groups are less likely to generate?
- Can staff explain and act on the output without specialized AI expertise?
Those aren't side questions. They're production questions.
An Implementation Checklist for Production Systems
Most ai health monitoring failures are predictable. Teams skip boring infrastructure work because the model demo creates false confidence. Then launch week exposes gaps in identity mapping, alert routing, version control, and debugging.
What to build before launch
Use this as a practical preflight list.
- A stable ingestion contract: Define canonical event schemas for wearable and clinical inputs. Don't let each device integration invent its own field meanings.
- Feature reproducibility: Make sure training features and serving features come from the same transformation logic. If your offline notebook computes heart rate variability one way and production computes it another way, your validation won't mean much.
- Patient identity resolution: Decide how records from apps, devices, and clinical systems map to one patient. Errors here are catastrophic.
- Alert policy versioning: Treat thresholds, routing rules, and suppression logic as versioned artifacts. A changed escalation rule can alter clinical behavior as much as a new model.
- Review tooling: Clinicians and operators need a fast way to inspect the event history behind an alert and mark it useful, not useful, or inconclusive.
- Rollback paths: Every model and rules release should have a low-risk rollback option.
What teams usually underestimate
The first issue is observability depth. Basic logs aren't enough. You need per-inference traces that show input version, model version, latency, output, fallback behavior, and downstream alert delivery status.
The second issue is orchestration sprawl. Once teams combine LLM-based summarization, structured risk scoring, multimodal inputs, and vendor-specific APIs, they often hardcode too much behavior into the application itself. That makes every prompt tweak, provider change, and routing update feel like a redeploy.
A cleaner pattern is to keep application code focused on product logic while externalizing AI configuration, model routing, and detailed call tracing into a unified backend. That reduces release friction and gives product, engineering, and operations teams a shared view of what happened on each call.
Operational advice: If updating prompt behavior, provider selection, or model fallback requires an app release, your iteration loop is too slow for production AI.
Another frequent miss is cost visibility. Continuous monitoring systems can trigger many downstream AI or analytics calls, especially when they summarize trends or generate clinician-facing explanations. If nobody can see cost per workflow and correlate that to actual clinical value, spend drifts unchecked.
A stronger production setup usually supports:
For startup teams and small product groups, this matters even more. You usually don't have separate platform, MLOps, and clinical informatics teams. The more of the AI runtime surface you can centralize and observe cleanly, the more time you keep for the actual care workflow.
Getting Started and Future Trends
Start with one narrow monitoring workflow that already has a clear human owner. Don't begin with "AI for all vitals." Begin with a specific use case such as risk flagging for a chronic cohort, post-discharge trend review, or clinician summaries attached to device alerts.
Build the production loop first. That means trustworthy ingestion, reproducible features, reviewable alerts, subgroup checks, and feedback capture. Add model sophistication after that. Teams that reverse the order usually spend months debugging infrastructure debt they created early.
The broader direction is clear. Monitoring is moving toward continuous, data-driven care, but the winning systems won't be the ones with the flashiest model demo. They'll be the ones that clinicians can trust, operators can debug, and product teams can evolve safely without turning every change into a deployment fire drill.
If you're building AI features and don't want prompt logic, model routing, observability, and cost tracking scattered across your app, Supagen gives you a unified production layer to manage them in one place. It's a practical fit for teams shipping fast who still need auditable updates, per-call visibility, and less redeploy pain.