Agentic AI Framework: A Guide for Production Systems

You probably have one already: a demo agent that looked sharp in a notebook, answered the happy-path prompt correctly, and even called a tool once or twice. Then it hit a real product environment. Latency spiked. Tool calls failed halfway through a task. The prompt that worked yesterday started drifting after a small model change. Support asked why the agent refunded the wrong order. Finance asked why the bill jumped. Engineering asked for logs, and there weren't enough of them.
That's the production gap.
Often, projects don't fail because the model is too weak. They fail because the system around the model is too thin. A good model can reason, but it can't by itself manage retries, tool permissions, state, versioning, audit trails, or fallbacks. That work lives in the agentic AI framework. If the model is the brain, the framework is the operating system, nervous system, and black box recorder all at once.
Table of Contents
- Why Your AI Needs More Than Just a Brain
- The Anatomy of an Agentic AI Framework
- Blueprints for Building Your AI Agent
- How to Implement an Agentic AI Framework
- Agentic AI in Action Real World Examples
- Best Practices for Production-Ready Agents
- The Future Is Agentic and It Needs a Foundation
Why Your AI Needs More Than Just a Brain
The first version of an agent usually cheats without meaning to. It runs with clean inputs, friendly prompts, stable APIs, and a developer watching every step. Production removes all of that. Users ask vague questions, tools return partial data, sessions stretch across time, and every mistake becomes visible to a customer or teammate.
That's why an agentic AI framework matters. It isn't extra ceremony around an LLM call. It's the runtime that helps an agent perceive what's happening, decide what to do next, coordinate tool calls, retain useful context, and stay inside operational limits. Without that layer, you don't have an agent in any meaningful production sense. You have a clever prompt with access to a few functions.
The business interest is moving fast. The agentic AI market was estimated at $7.6 billion in 2026 and is projected to reach $236 billion by 2034, which implies about 31x growth and a compound annual growth rate above 40%. The same industry summary also attributes a $47.1 billion market forecast for 2030 to IDC, as noted in Digital Applied's collection of agentic AI statistics. That doesn't mean every agent product will work. It means teams are now treating frameworks for agents as a serious software category, not a side project.
The demo problem
A demo proves that a model can produce a good answer once. Production asks much harder questions:
- Can it recover from a failed tool call without looping or corrupting state?
- Can it explain what happened when a user disputes an action?
- Can it stay within cost and latency budgets when traffic rises?
- Can it degrade safely when one provider, API, or dependency starts failing?
Practical rule: If you can't inspect the agent's steps, replay them, and constrain them, you don't have a production system yet.
The framework is the missing layer
When hiring a brilliant employee, intelligence helps, but it's not enough. Such an employee still needs access rules, a task queue, a place to store notes, escalation paths, and a manager who notices when something goes off track. The agentic AI framework plays all of those roles.
Teams often spend too much time tuning the brain and too little time building the body around it. In practice, the body is what keeps the feature alive.
The Anatomy of an Agentic AI Framework
A real agentic AI framework looks less like a wrapper and more like a coordinated system. The easiest mental model is a strong human operator inside a company. That person can understand goals, remember context, use internal tools, follow policy, ask for approval, and leave a trail of what they did.
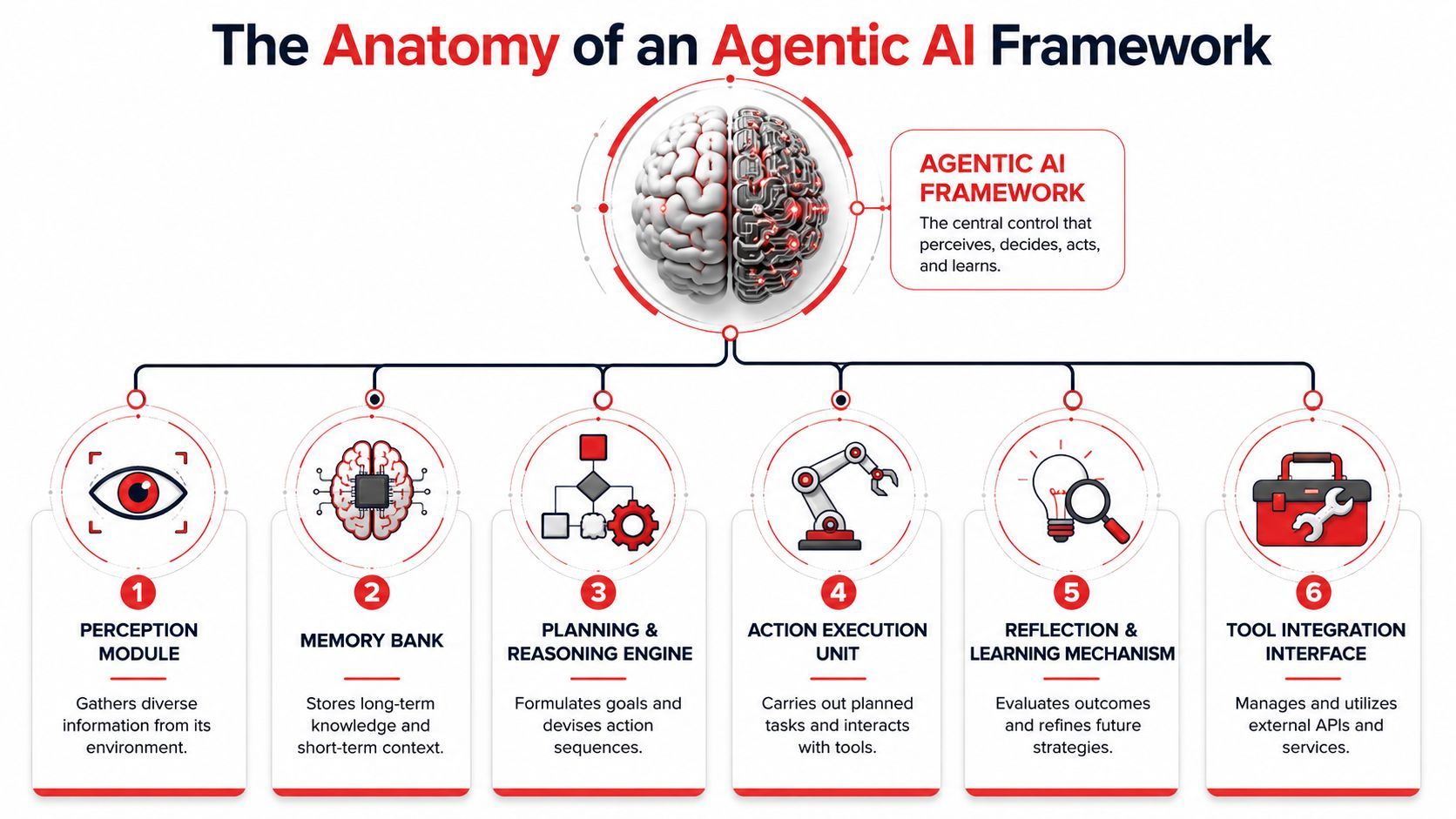
A model is only one part of the worker
The model is the brain. It interprets instructions, reasons over available context, and proposes next steps. But a brain by itself can't ship work.
You also need the following parts:
- Planning helps the agent break a goal into steps. Even simple tasks benefit from this. “Find the shipment, check delay reason, draft response, ask for approval” is much safer than one giant leap.
- Memory gives the agent continuity. Short-term memory holds session context. Longer-term memory can store policies, user preferences, or prior outcomes. Bad memory design causes repeated mistakes or context pollution.
- Tool use connects the agent to real systems such as Stripe, Slack, Jira, HubSpot, internal APIs, or a retrieval layer. Such integration makes an agent useful, and also where it becomes risky.
- Safety defines the boundaries. Which tools can be used? Which actions require approval? What data should never be exposed back to the user?
- Observability records what happened. Which prompt was used? Why did the agent choose a specific tool? What input changed the plan?
- Orchestration keeps the whole thing moving in the right order.
Orchestration is the part frequently underestimated. It decides when to call a tool, when to retry, when to stop, when to request human review, and how to recover from partial failure. That's why Exabeam's overview of agentic AI frameworks correctly frames an agentic framework as the runtime architecture for perception, reasoning, planning, and action across external systems, with orchestration, tool integration, memory, monitoring, and human oversight as core capabilities.
This walkthrough is worth a quick watch before going deeper:
What production systems add
Prototype agents often bundle all logic into one loop. Production systems separate concerns.
The best agent stacks don't pretend the model is reliable on its own. They assume every external step can fail and design around that.
A practical analogy helps here. If the model is an employee's judgment, orchestration is their manager, memory is their notebook, tools are their software access, safety is company policy, and observability is the audit log. Remove any one of those in a real business process and things get messy fast.
Blueprints for Building Your AI Agent
Once the pieces are in place, the next question is structure. Agents need repeatable behavior patterns. I think of these as blueprints, not abstractions. A blueprint tells you how the agent should think, act, and recover.
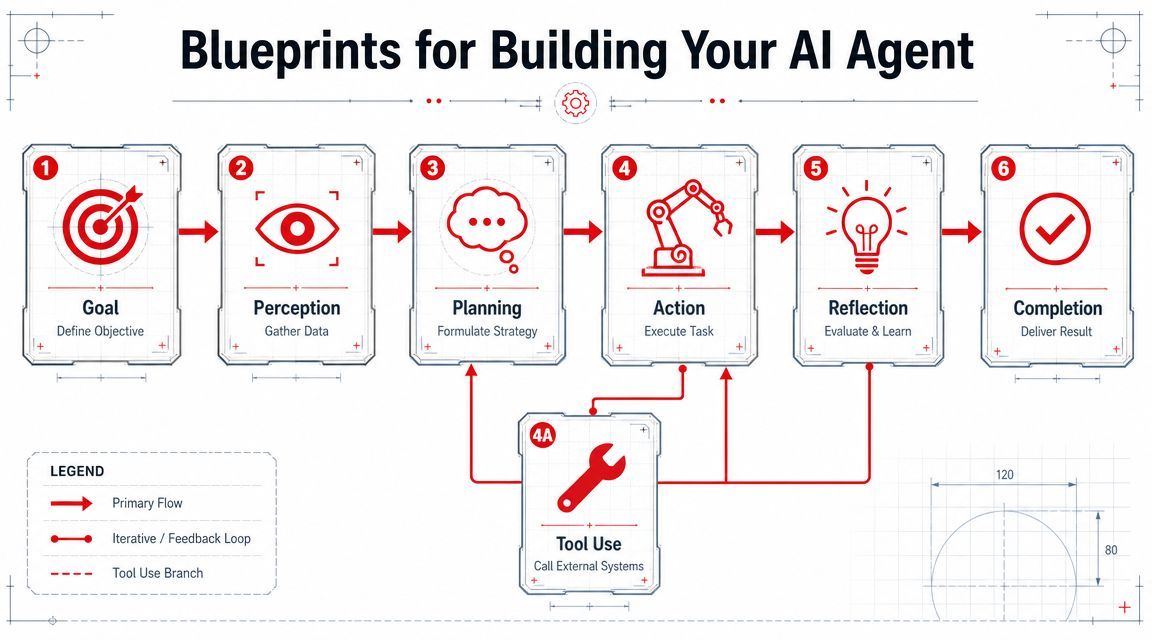
The ReAct loop for bounded work
The most useful starting pattern is the ReAct loop: reason, act, observe, repeat.
Take a small goal: find the best local coffee shop and check whether it's open. A production-minded ReAct flow looks like this:
- The agent interprets the request and decides it needs location and business data.
- It calls a search or maps tool.
- It inspects the results and picks promising candidates.
- It calls a second tool to verify hours or current status.
- It returns an answer with uncertainty handled explicitly if a tool response is incomplete.
That pattern works well for support, operations, lightweight research, and internal copilots because the loop stays tight. It also keeps failure visible. If step three goes wrong, you know where.
Multi-agent patterns for specialization
Multi-agent systems can help, but only when roles are distinctly different. A common productive split is a researcher agent and a writer agent. The researcher gathers facts from approved sources or internal docs. The writer turns those findings into customer-facing language.
This works because each agent has a smaller job and a clearer tool set. It fails when teams create many agents merely for show. If every agent can do everything, coordination becomes overhead.
A good rule is simple:
- Use one agent when the task is sequential and bounded.
- Use multiple agents when specialization improves quality or safety.
- Avoid multi-agent fan-out if you can't monitor each handoff clearly.
Hierarchical planning for larger goals
Some tasks are too broad for a flat loop. A manager-worker pattern helps there. One planner agent decomposes the goal into sub-tasks, then hands them to worker agents or deterministic services.
For example, “prepare a weekly sales operations summary” might break into:
- gather CRM changes
- summarize support escalations
- identify pipeline blockers
- draft stakeholder notes
The manager shouldn't do all the work itself. It should assign, validate outputs, and escalate exceptions.
Operator's advice: Start with the simplest blueprint that can finish the job. Most teams add agent complexity much earlier than they add controls.
The blueprint matters because it shapes everything downstream: prompts, tool boundaries, logging, retry rules, and approval points. Good architecture reduces surprises before any prompt tuning starts.
How to Implement an Agentic AI Framework
There are three common implementation paths. Each can work. The right one depends on how quickly you need to ship, how much control you need, and whether you're willing to own production infrastructure around the agent.
Three implementation paths
The first path is open-source libraries. This usually means starting with tools like LangChain, Semantic Kernel, AutoGen, or similar orchestration libraries. They're good for getting a loop running quickly, testing tool calls, and exploring workflow patterns. The trade-off is that production concerns often spill into your app code. You end up wiring prompt versioning, retries, tracing, model routing, and provider-specific handling yourself.
The second path is open protocols. OpenAPI gives you a clean way to expose tools. MCP is becoming useful for standardizing how agents access tools and context across systems. This path is attractive when you want portability and cleaner boundaries between the agent runtime and the systems it touches. The downside is that protocols solve interoperability, not the full production stack. You still need monitoring, governance, fallback behavior, and cost controls.
The third path is a unified AI backend. This approach separates product logic from model and prompt plumbing. Teams integrate once, then manage prompts, routing, fallbacks, logs, and spending controls centrally instead of hardcoding them across services. For products that need to iterate quickly without constant redeploys, this is usually the cleanest production posture.
Implementation comparison
The mistake I see most often is treating these as mutually exclusive. They're not. Many strong stacks use a library for local agent logic, protocol-based tools for clean integration, and a backend layer for routing, observability, and governance.
What doesn't scale is mixing all concerns into application code. Once prompts, provider logic, fallback trees, and per-call debugging are scattered across endpoints, every model change becomes a release process. That's fine for an experiment. It's painful for a product.
Agentic AI in Action Real World Examples
The most useful agent systems today don't look like science fiction. They look like narrow operators embedded in ordinary workflows.
Support workflows
An e-commerce support agent can read a customer message, detect whether the issue is about a late shipment, pull order status from an internal API, and draft a reply for human approval. The value isn't just faster text generation. It's the combination of context, action, and handoff.
A good version of this agent doesn't auto-send every response. It only handles the bounded parts well: lookup, summarization, tone matching, and suggested resolution. The human still approves edge cases, refunds, or policy-sensitive actions.
Operational triage
A DevOps agent can watch an alert stream, query logs or metrics tools, and summarize probable causes in Slack. That's useful because engineers waste time on collection and formatting before they ever start diagnosis.
The agent shouldn't restart services or change infrastructure by default. It should gather evidence, propose likely causes, and attach the relevant traces or logs. In practice, that's where teams get most of the value early without taking on unnecessary risk.
Content systems
A content pipeline can use multiple bounded agents: one researches approved source material, another drafts, and a third checks style or structure against a brand guide. This pattern works well when the workflow is repetitive and the review criteria are clear.
Independent commentary from 2025 to 2026 warns that many deployments are still assistive rather than fully autonomous, and that scalability, interoperability, governance, and infrastructure costs remain major blockers. The better near-term move is to define bounded autonomy for a specific workflow, then measure latency, cost, human override rate, and failure modes, as discussed in this agentic AI commentary on practical scope and ROI.
Teams get into trouble when they ask one agent to own an entire job. Teams get value when they carve out the repeatable slice that benefits from judgment plus tool use.
That distinction matters. “Autonomous” sounds impressive. “Useful and controllable” is what survives production.
Best Practices for Production-Ready Agents
Most agent failures in production are predictable. They come from the same handful of shortcuts: too much autonomy, weak tracing, loose tool permissions, and no spend discipline.
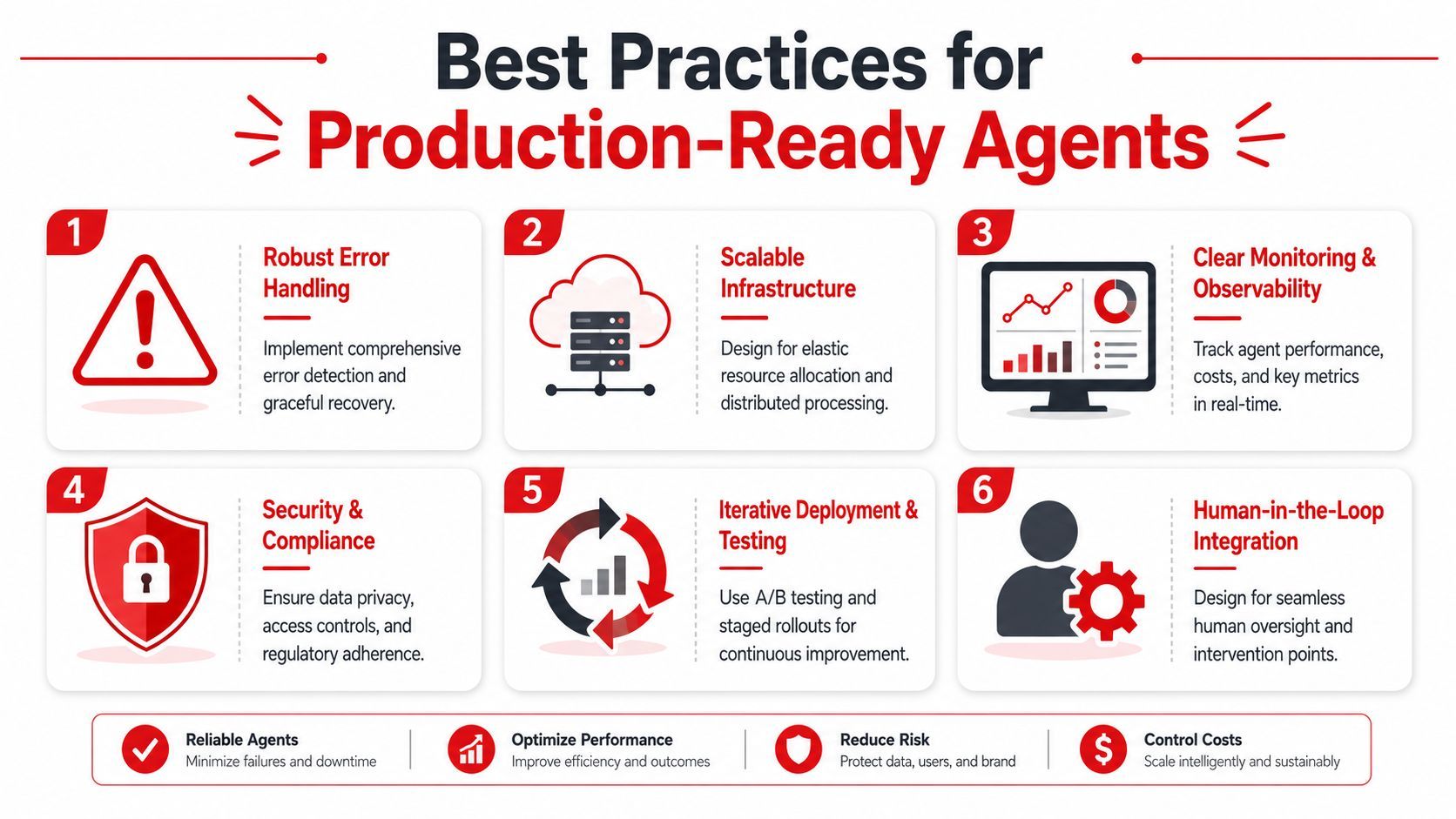
Keep autonomy bounded
Start with a narrow workflow that has a clear success condition. Good examples include triaging support tickets, summarizing incidents, collecting underwriting inputs, or drafting responses for approval. Bad starting points are goals like “manage customer support” or “run growth operations.”
Bounded autonomy forces useful questions:
- What action is the agent allowed to take on its own
- What requires approval
- What should force a fallback to a human
- What should the agent never store in memory
This is also the right way to manage trust. Security guidance has shifted beyond prompt injection toward a broader view across perception, reasoning, action, and memory. The Cloud Security Alliance's 2026 Agentic Trust Framework adds four autonomy levels, reflecting a move from binary access control to earned trust, as discussed in MIT Sloan's overview of agentic AI security essentials.
Treat observability as a product feature
If a user says the agent behaved incorrectly, you need more than the final response. You need the chain of events around it.
Track things like:
- Prompt version used for the run
- Model and provider selected
- Tool calls attempted
- Input and output payload changes
- Latency by step
- Whether a fallback or override occurred
Observability isn't only for debugging. It improves product decisions. You can see where users abandon flows, where tool choice is unstable, and which tasks create cost without enough value.
A trace is often more valuable than another round of prompt edits. Teams fix faster when they can see the exact step where the workflow drifted.
Secure the action layer
Prompt injection gets attention because it's easy to explain. Production risk is broader than that. The dangerous parts are usually permissions, tool execution, and memory retention.
A practical security checklist looks like this:
- Scope tool access tightly. Give each agent the smallest useful set of actions.
- Separate read from write. Read-only tools are safer defaults.
- Require approval for consequential actions. Refunds, account changes, outbound messages, and infrastructure mutations should have clear gates.
- Audit memory writes. Don't let the agent persist bad state or user-injected junk unnoticed.
- Map system interactions. Know what the agent can reach, directly and indirectly.
Plan for failure and spend
Agents fail in more ways than normal request-response systems. A tool can timeout. A model can produce malformed arguments. A retrieval step can return stale context. Another service can return a valid-looking but incomplete result.
Design for graceful failure:
- Retry only when the failure mode makes sense.
- Fall back to a safer path when confidence drops.
- Hand the task to a human when the action is sensitive.
- Stop loops aggressively.
Cost control deserves the same attention. Multi-step agents can consume far more budget than a simple chat feature because every retry, reflection step, or tool result adds context and latency. If you don't watch spend at the task level, you'll discover it too late.
A mature agent system isn't the one that acts most freely. It's the one that remains debuggable, governable, and affordable after the novelty wears off.
The Future Is Agentic and It Needs a Foundation
The direction is clear. A spring 2025 survey reported by MIT Sloan found 35% of respondents had adopted AI agents by 2023, while 44% planned to deploy them soon, and Gartner projections cited there say 40% of enterprise applications will include task-specific AI agents by the end of 2026, according to MIT Sloan's explanation of agentic AI adoption. The opportunity is real.
The winning products won't come from agents that merely sound smart. They'll come from systems with strong orchestration, clear boundaries, useful memory, solid logs, and predictable costs. The future is agentic. The part that matters is the foundation under it.
If you're building AI features or agents and want the production layer handled cleanly, Supagen is worth a look. It gives teams a unified AI backend for prompt management, model routing, observability, fallbacks, and cost tracking, so you can ship faster without hardcoding those concerns across your app.